Retaining by doing the role of on Policy data in mitigating forgetting
Table of Contents
Source: “Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting,” arXiv: arXiv:2510.18874.
Introduction
Background
Adapting language models (LMs) to new tasks via post-training carries the risk of degrading existing capabilities, known as catastrophic forgetting. This phenomenon has been observed in both supervised fine-tuning (SFT) for instruction following and reinforcement learning (RL) for preference alignment. However, the comparative susceptibility of SFT and RL to forgetting remains underexplored. The paper addresses this by comparing their forgetting patterns across diverse tasks and models.
Research Gap
While prior work has noted forgetting in LM post-training, there is limited understanding of how SFT and RL differ in their forgetting behaviors. Existing studies often focus on one method or lack systematic comparisons across tasks and models. The role of on-policy data in mitigating forgetting has not been thoroughly investigated.
Hypothesis
RL is more robust to forgetting than SFT due to its mode-seeking nature and use of on-policy data, allowing it to maintain prior knowledge while adapting to new tasks.
Conclusion
The paper demonstrates that RL consistently forgets less than SFT across various LM families and tasks, attributing this to on-policy data usage. It highlights the potential of approximately on-policy data for efficient forgetting mitigation.
Literature Review
Prior work on catastrophic forgetting in LMs includes studies on SFT and RL, but comparative analyses are scarce. Related efforts explore continual learning techniques, but focus less on post-training specifics. Concurrent work by Lai et al. and Shenfeld et al. also find RL forgets less, but attribute it differently.
Methodology
Baseline Methods
The baselines include SFT using responses from Llama-3.3-70B-Instruct, Self-SFT using filtered responses from the initial model, and RL via GRPO with KL regularization.
Proposed Modifications
The paper proposes using on-policy data in SFT, such as Iterative-SFT (updating data at each epoch) and SFT on RL-generated data, to reduce forgetting.
Experimental Setup
Experiments use Llama 3 and Qwen 2.5 models (1B to 8B parameters) on IFEval, MMLU, and Countdown tasks. Training for 2 epochs with AdamW, batch size 128/64, and specific learning rates. Evaluation measures gain on target task and drop on non-target tasks (MATH, WildJailbreak, WildGuardTest).
Experiment
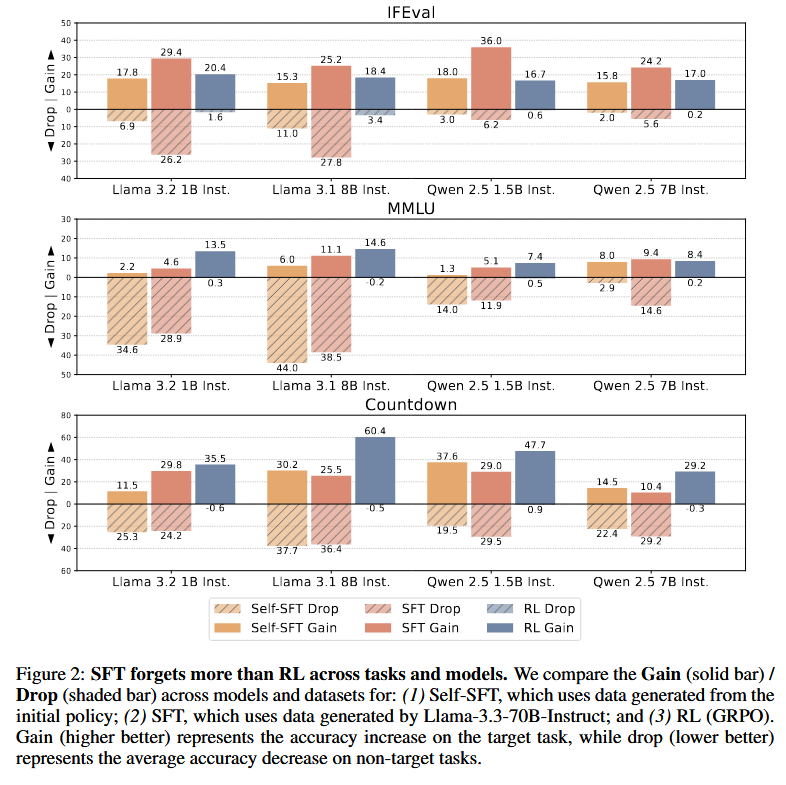
Main Findings
RL consistently shows less forgetting than SFT and Self-SFT across all tasks and models, achieving comparable or higher target performance. For example, on IFEval, RL gains 17-18% with drops of 0.2-3.4%, while SFT drops 15-27%. Simulations reveal that in multi-modal settings, mode-seeking RL preserves old modes better than mode-covering SFT.
Comparative Analysis
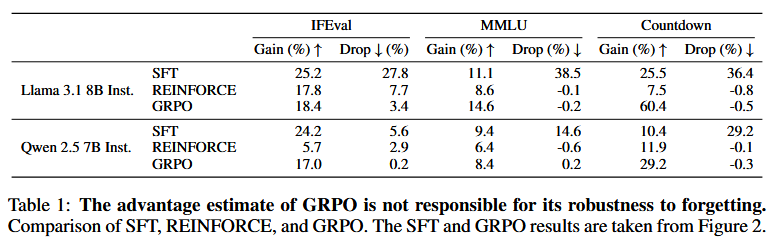
Compared to SFT, RL achieves similar gains but with much lower drops (e.g., RL drop 0.2% vs SFT 27% on IFEval). Ablations show on-policy data is key, not KL regularization or advantage estimation. Iterative-SFT reduces forgetting compared to Self-SFT, approaching RL’s performance.
Statistical Significance
Results are consistent across multiple runs and models, with clear trends in figures showing RL’s superiority. Ablations confirm on-policy data’s role through controlled experiments.
Discussion
Interpretation of Results
The mode-seeking behavior of RL, enabled by on-policy data, allows shifting to new modes without erasing old ones in multi-modal policies. This contrasts with SFT’s mode-covering approach, which redistributes mass and causes forgetting. Approximately on-policy data in SFT can mimic this effect.
Implications
For LM post-training, using RL or incorporating on-policy data in SFT can preserve existing capabilities. This has practical implications for efficient continual learning and safer model updates, especially in safety-critical applications.
Limitations
Experiments are limited to specific tasks and models; scaling to larger models or more diverse tasks may reveal different patterns. The theoretical analysis uses simplified Gaussian mixtures, which may not fully capture LM complexity.
Reference
[1] H. Chen, N. Razin, K. Narasimhan, and D. Chen, “Retaining by Doing: The Role of On-Policy Data in Mitigating Forgetting,” Dec. 03, 2025, arXiv: arXiv:2510.18874. doi: 10.48550/arXiv.2510.18874.