Agent Based automated claim matching with instruction Following llms
Table of Contents
Source: “Agent-based Automated Claim Matching with Instruction-following LLMs,” arXiv: arXiv:2510.23924.
Introduction
Background
Automated fact-checking pipelines rely on claim matching to identify claims that can be verified using the same evidence or fact-check. This task is crucial for scaling fact-checking efforts, as it helps in grouping related claims for efficient verification. Previous work has framed claim matching as a ranking problem or a binary classification task, with state-of-the-art results achieved using few-shot learning with instruction-following large language models (LLMs) based on manually crafted prompts. However, these approaches require human effort in prompt engineering, limiting automation. This paper addresses this gap by proposing an agent-based approach that automates prompt generation using LLMs themselves, aiming to reduce manual intervention while maintaining or improving performance.
The motivation stems from the need to overcome limitations in existing LLM-based claim matching methods. Earlier studies, such as Pisarevskaya and Zubiaga (2025), demonstrated strong results with hand-crafted prompts but highlighted the potential for automated prompt engineering to enhance scalability. Inspired by advancements in LLM agents and multi-agent systems, the authors draw from related fields like paraphrase detection and natural language inference to adapt LLMs for this task. By leveraging LLMs to generate prompts, the approach seeks to capture nuanced understandings of claim matching without predefined templates.
Objective
The primary objective of this work is to develop a novel agent-based pipeline for automated claim matching using instruction-following LLMs, specifically designed to outperform existing state-of-the-art methods that rely on manual prompt engineering. The authors aim to investigate automated prompt engineering techniques, including the selection of few-shot examples and the generation of prompts by LLMs, to reduce human effort and enhance performance.
Additionally, the study seeks to compare the proposed agent-based approach against baseline methods, such as random or similarity-based few-shot selection and prompt-tuning, while exploring the use of different LLMs for prompt generation and classification. A key goal is to gain insights into how LLMs understand the claim matching task, revealing effective prompt structures and potential limitations.
Conclusion
This paper introduces a pioneering agent-based pipeline for automated claim matching, leveraging instruction-following LLMs to generate prompts and perform binary classification. The key contributions include the development of automated prompt engineering methods that select optimal few-shot examples and generate effective prompts, outperforming state-of-the-art results from manual prompt designs and prompt-tuning approaches. By demonstrating that LLM-generated prompts can achieve superior performance, the work advances the automation of fact-checking pipelines.
The experimental results show that prompts generated by smaller LLMs, such as Llama, can effectively guide larger or different models like Mistral, achieving F1 scores up to 96.9%. This highlights the potential for resource-efficient implementations and the transferability of prompts across models. Furthermore, the study provides insights into LLMs’ understanding of claim matching, emphasizing the importance of concepts like ‘same event’ or ‘topic’ in prompt design, while identifying limitations such as over-reliance on consistency markers.
Overall, the agent-based approach not only improves performance but also opens avenues for further research, including multi-iteration prompt refinement, multilingual applications, and integration with other NLP tasks in fact-checking.
Literature Review
Claim matching has been addressed in prior research as both a ranking task and a classification problem. Ranking-based approaches, such as those by Shaar et al. (2020) and Kazemi et al. (2021, 2022), focus on retrieving relevant claims from large corpora. More recently, classification frameworks have emerged, including Choi and Ferrara (2024a,b) who treat it as a textual entailment task with three classes. Pisarevskaya and Zubiaga (2025) framed claim matching as a binary classification using paraphrase detection, natural language inference, or direct matching prompts, achieving state-of-the-art few-shot results with LLMs but relying on manual prompt templates.
The rise of LLM agents has enabled complex task automation. Works like Zhao et al. (2024) and Wang et al. (2024) demonstrate agents that interact and complete tasks, while multi-agent systems (Guo et al., 2024; Liang et al., 2024) enhance collaboration. This paper adapts a pipeline interaction inspired by Chan et al. (2023) and Fang et al. (2025), where one agent generates prompts and another performs classification.
Automated prompt engineering aims to optimize prompts without manual effort. Techniques from Liu et al. (2021) and Schulhoff et al. (2025) include generating prompts with LLMs (Reynolds and McDonell, 2021; Zhou et al., 2023; Ye et al., 2024). Prompt-tuning, as in Lester et al. (2021) and Liu et al. (2022), fine-tunes model parameters for efficiency. The authors compare their agent-based method to prompt-tuning on the same templates, showing superior performance.
Overall, while prior work has advanced claim matching and prompt automation separately, this study uniquely combines them in an agent-based pipeline for this specific task.
Methodology
The study uses the ClaimMatch dataset from Pisarevskaya and Zubiaga (2025), based on Nakov et al. (2022), with 500 matching and 500 non-matching claim pairs in the test set. Few-shot examples are drawn from the original work, and additional pairs are used for prompt-tuning.
Experiments begin with automated selection of few-shot examples, comparing random selection, similarity-based sorting (using All-MiniLM-L6-v2 for semantic similarity), and borderline approaches against the original manual selection. This is tested on three hand-crafted prompt templates: CM-t (direct matching), PD-t (paraphrase detection), and NLI-t (natural language inference).
The core agent-based pipeline consists of two steps: (1) Prompt generation, where LLMs (Mistral-7B, Llama-3-8B, and larger variants Mistral-Small-24B, Llama-3.3-70B) are prompted to create new prompts based on few-shot examples, without explicit task definitions to assess LLM understanding. (2) Binary classification, where generated prompts are used for claim matching with the same or different LLMs, evaluating combinations like Mistral with Llama prompts.
Models are quantized for efficiency, and experiments compare performance against SOTA few-shot and prompt-tuning baselines. Prompt-tuning uses PEFT with 5 epochs on the same templates.
This setup allows investigation of cross-model prompt transferability and insights into LLM interpretations of claim matching.
Experiment
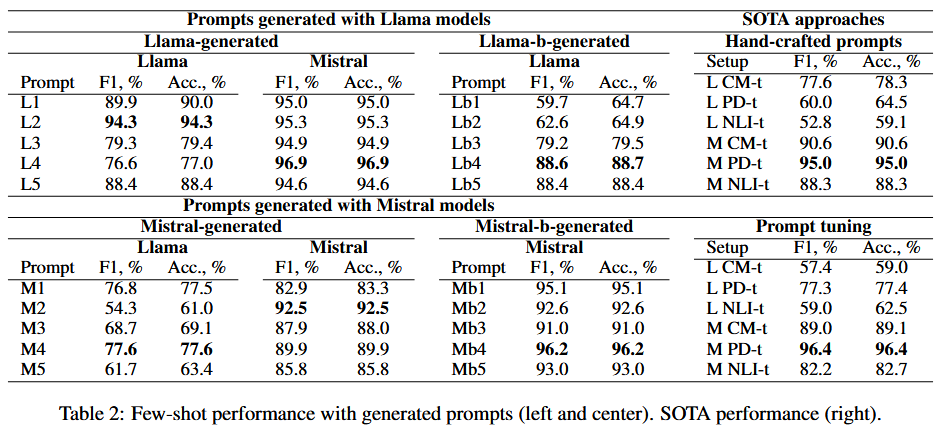
Few-shot example selection shows model-dependent performance: Mistral benefits from sorted examples on CM-t and PD-t, while Llama improves with random or borderline on all templates, outperforming SOTA. However, the original manual selection remains robust for Mistral.
LLM-generated prompts significantly outperform SOTA, with Llama prompts yielding the best results (e.g., L2 prompt achieving 96.9% F1 and accuracy for Mistral). Cross-model usage (e.g., Llama prompts for Mistral) proves effective, saving resources, and even surpasses prompt-tuning baselines. Larger models do not necessarily generate better prompts, as smaller Llama prompts outperform those from larger variants.
Error analysis reveals that effective prompts emphasize ‘same event’ or ‘topic’, but limitations include false negatives from minor variations and over-strict consistency checks. Mistral prompts sometimes lead to worse performance due to misinterpretations, while Llama’s broader markers reduce false negatives.
Overall, the agent-based pipeline demonstrates superior automation and performance, with insights into LLM task understanding, though further refinements like step-by-step reasoning are suggested for handling edge cases.
Reference
[1] Pisarevskaya, Dina and Zubiaga, Arkaitz. Zero-shot and few-shot learning with instruction-following LLMs for claim matching in automated fact-checking. In Proceedings of the 31st International Conference on Computational Linguistics, pages 9721–9736, Abu Dhabi, UAE. Association for Computational Linguistics, 2025. [2] Barrón-Cedeño, Alberto et al. Overview of checkthat!2020: Automatic identification and verification of claims in social media. Preprint, arXiv:2007.07997v1, 2020. [3] Shaar, Shaden et al. That is a known lie: Detecting previously fact-checked claims. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3607–3618, Online, 2020. [4] Choi, Eun Cheol and Ferrara, Emilio. Automated claim matching with large language models: Empowering fact-checkers in the fight against misinformation. In Companion Proceedings of the ACM Web Conference 2024, WWW ’24, page 1441–1449, New York, NY, USA. Association for Computing Machinery, 2024. [5] Zhao, Yongchao et al. Expel: LLM agents are experiential learners. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’24/IAAI’24/EAAI’24. AAAI Press, 2024. [6] Liu, Pengfei et al. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55:1–35, 2021. [7] Lester, Brian et al. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic, 2021.