Conftuner training large language models to express their confidence verbally
Table of Contents
Source: “ConfTuner: Training Large Language Models to Express Their Confidence Verbally,” arXiv:2508.18847.
Introduction
Background
Large Language Models (LLMs) are increasingly deployed in high-stakes domains such as science, law, and healthcare, where accurate expressions of uncertainty are essential for reliability and trust. However, current LLMs often generate incorrect answers with high confidence, a phenomenon known as overconfidence. This undermines trust and poses challenges for safe LLM deployment. Recent efforts have focused on calibrating LLMs’ verbalized confidence, but existing approaches rely on prompt engineering or fine-tuning with heuristically generated uncertainty estimates, which have limited effectiveness and generalizability.
Objective
The central research question is whether LLMs can be naturally calibrated during training without relying on ground-truth confidence scores or proxy confidence estimates. Inspired by proper scoring rules in classical machine learning, the authors propose ConfTuner, a fine-tuning method using a tokenized Brier score to incentivize LLMs to express confidence that reflects their true likelihood of correctness.
Conclusion
ConfTuner provides accurate confidence estimates that outperform baselines in calibration metrics, generalize across tasks and models, and enable practical benefits like improved self-correction and cost-effective model cascades. The method advances trustworthy LLM systems by aligning verbalized confidence with actual reliability.
Literature Review
Prior work on LLM calibration includes prompt-based methods for eliciting verbalized confidence, which have limited effects. Training-based approaches fine-tune LLMs with proxy confidence scores from heuristics like model accuracy on similar questions or consistency across responses. However, these proxies introduce bias and noise. Traditional calibration in classifiers uses proper scoring rules like Brier score, but adapting this to verbalized confidence in LLMs is novel. ConfTuner extends this by defining proper scoring rules for tokenized confidence expressions.
Methodology
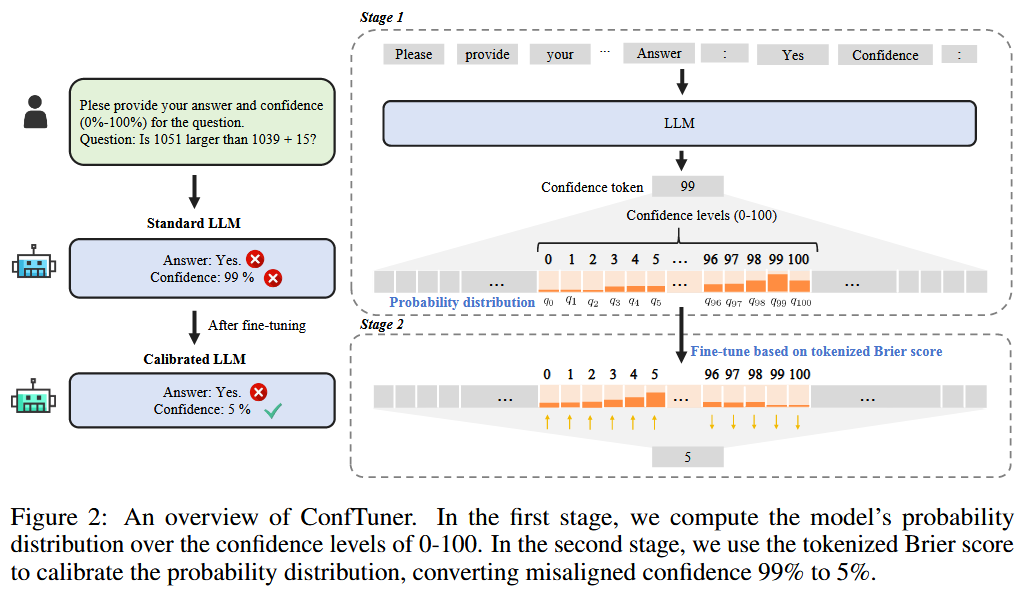
ConfTuner consists of two steps:
- Compute probability distribution over confidence tokens (e.g., 0-100%) by extracting logits for confidence tokens after the LLM generates an answer.
- Fine-tune using the tokenized Brier score loss, which penalizes the squared error between predicted confidence and correctness. The loss is proven to be a proper scoring rule, ensuring calibration. Training uses LoRA on HotpotQA, with minimal overhead, no ground-truth confidences needed.
Experiment
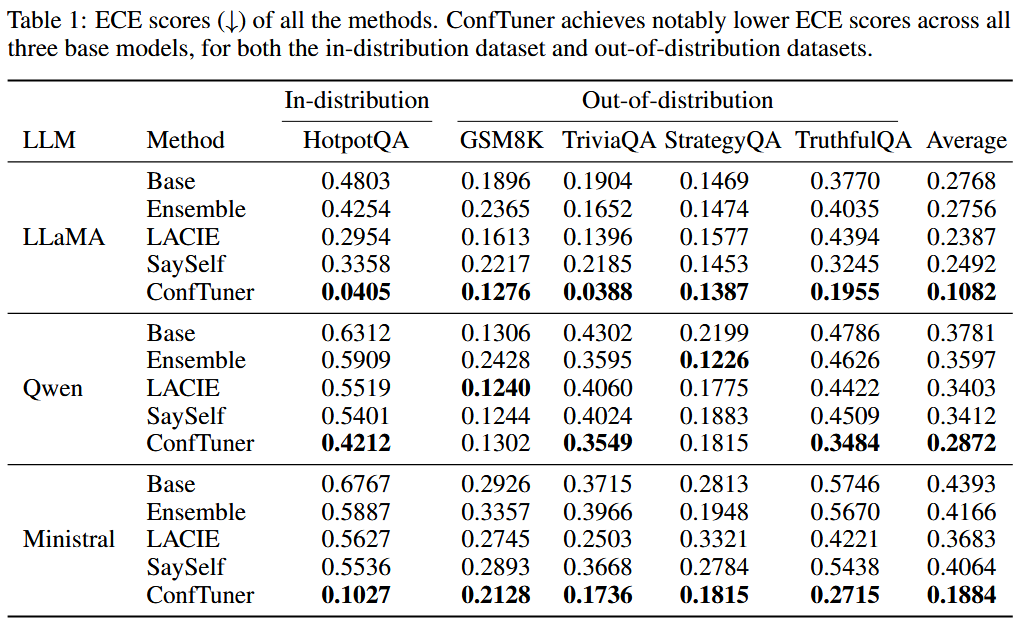
ConfTuner outperforms baselines (Base, Ensemble, LACIE, SaySelf) in ECE and AUROC across LLaMA, Qwen, and Ministral models on HotpotQA and out-of-distribution datasets (GSM8K, TriviaQA, StrategyQA, TruthfulQA). It generalizes to linguistic confidence (high/medium/low) and implicit expressions, and calibrates black-box models like GPT-4o. Ablations show efficiency (4 min training, 2,000 samples), and applications include better self-correction and model cascades with up to 9.3% accuracy gains.
Reference
[1] Y. Li, M. Xiong, J. Wu, and B. Hooi, “ConfTuner: Training Large Language Models to Express Their Confidence Verbally,” Aug. 26, 2025, arXiv: arXiv:2508.18847. doi: 10.48550/arXiv.2508.18847.