Why diffusion models don’t memorize the role of implicit dynamical regularization in training
Table of Contents
Source: “Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training,” The Thirty-ninth Annual Conference on Neural Information Processing Systems
Introduction
Background
Diffusion models have revolutionized generative AI, achieving state-of-the-art performance in tasks like image, audio, and video generation. However, a key challenge is understanding why they generalize well without memorizing training data, despite being theoretically capable of reproducing exact samples. This paper explores the role of training dynamics in this phenomenon.
Research Gap
While previous studies have observed that diffusion models memorize training data for small datasets but generalize for larger ones, the underlying mechanisms—particularly the role of training dynamics in creating implicit regularization—remain poorly understood. Existing explanations focus on architectural biases or finite learning rates, but these do not fully account for the observed scaling with dataset size.
Hypothesis
The training dynamics of diffusion models exhibit implicit regularization through spectral bias, leading to two timescales: a short τ_gen for generalization and a longer τ_mem ∝ n for memorization, allowing early stopping to prevent memorization.
Conclusion
This work demonstrates that implicit dynamical regularization in training dynamics is key to preventing memorization in diffusion models, expanding the generalization regime through early stopping. The findings bridge numerical observations with theoretical insights, providing practical guidelines for robust DM training.
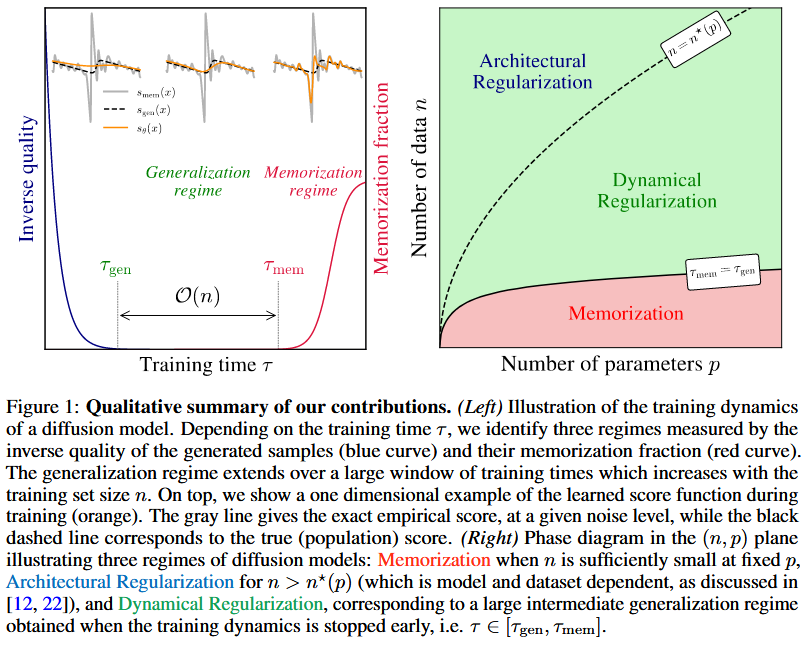
Literature Review
The paper reviews empirical studies on memorization in DMs (e.g., Stable Diffusion), theoretical works on score learning in high-dimensional limits, and spectral bias in neural networks. It builds on prior analyses of generalization-memorization transitions, early stopping benefits, and dynamical regularization mechanisms.
Experimental Design
Baseline Methods
U-Net architectures with varying widths (W=8 to 64) for score estimation in DDPMs, trained on CelebA. RFNN with random features for analytical tractability in high-dimensional limit.
Proposed Modifications
Vary dataset size n (128 to 32768) and model capacity p (via U-Net width W). Monitor training dynamics with early stopping at different τ. Use RFNN to derive spectral properties analytically.
Experimental Setup
CelebA downsampled to 32x32 grayscale. U-Nets trained with SGD, batch size min(n,512), diffusion time t=0.01 for loss monitoring. Metrics: FID against 10K test samples, f_mem via nearest neighbor distance (k=1/3). RFNN in high-dim limit with tanh activation, Gaussian data.
Results
Main Findings
Training exhibits two phases: FID reaches minimum at τ_gen ≈ 100K (independent of n), then stabilizes; f_mem starts at 0 and increases after τ_mem ∝ n. RFNN theory predicts τ_mem ∝ n via eigenvalue spectrum, with generalization loss decreasing as n increases.
Comparative Analysis
Compared to smaller n, larger n delays memorization (τ_mem increases), with generalization window widening. Varying p shows τ_mem ∝ n/W, confirming dynamical over architectural regularization. RFNN matches U-Net behavior, validating theory.
Statistical Significance
Results averaged over 5 test sets for FIDs, 5 noise realizations for losses. f_mem with 95% CI from 1000 bootstrap samples. Scaling τ_mem ∝ n confirmed with rescaled plots collapsing curves.
Discussion
Interpretation of Results
The two timescales arise from spectral bias: low-frequency components (population score) learned quickly, high-frequency (dataset-specific) learned later. Dynamical regularization stabilizes smooth approximations, preventing early memorization and allowing generalization via early stopping.
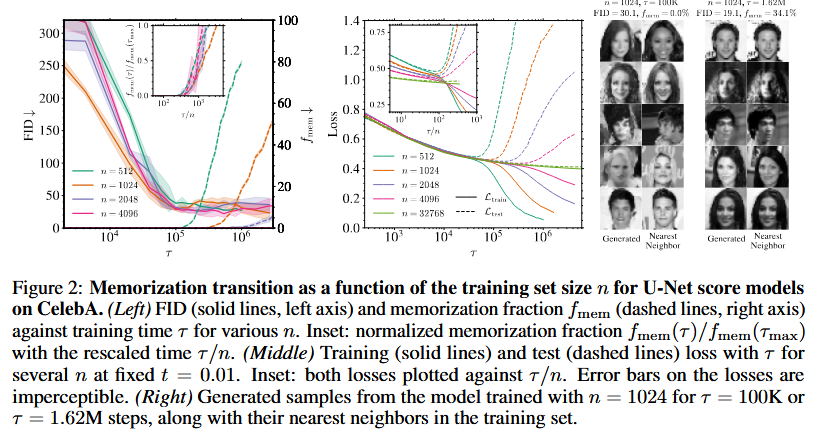
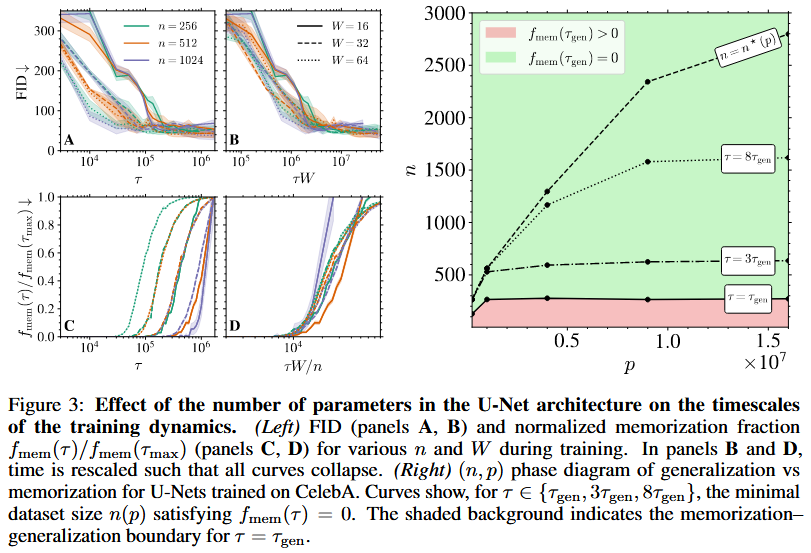
Implications
Early stopping at τ_gen prevents memorization in data-scarce settings. Provides guidelines for training DMs: monitor f_mem, stop when generalization loss increases. Extends to other score-based methods like flow matching.
Limitations
Experiments on unconditional CelebA; conditional settings and broader datasets need exploration. Theoretical analysis uses simplified models (RFNN, Gaussian data); real architectures and data distributions may differ. Limited p range; full (n,p) phase diagram requires wider exploration.
Reference
[1] T. Bonnaire, R. Urfin, G. Biroli, and M. Mezard, “Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training,” presented at the The Thirty-ninth Annual Conference on Neural Information Processing Systems, Oct. 2025. Accessed: Dec. 11, 2025. [Online]. Available: https://openreview.net/forum?id=BSZqpqgqM0