Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model
Table of Contents
Source: “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?,” The Thirty-ninth Annual Conference on Neural Information Processing Systems
Introduction
Background
Recent breakthroughs in reasoning-centric Large Language Models (LLMs), such as OpenAI-o1 and DeepSeek-R1, have been largely driven by Reinforcement Learning with Verifiable Rewards (RLVR). In this paradigm, models are trained on tasks like mathematics and coding where the reward (correctness) is automatically computable. The common industry belief is that RLVR allows models to “self-evolve,” discovering novel reasoning strategies (like self-reflection or trial-and-error) that exceed the capabilities of their original base models.
Objective
The researchers set out to rigorously test whether current RLVR methods genuinely expand an LLM’s reasoning “boundary” or if they simply teach the model to find correct answers more efficiently within a search space it already possesses. They utilize the pass@k metric (the probability of getting at least one correct answer in $k$ attempts) to map the true potential of both base and RL-trained models.
Conclusion
The study yields a surprising “cold water” finding: Current RLVR does not elicit fundamentally new reasoning patterns. While RLVR significantly improves “sampling efficiency” (making the model more likely to get the answer right on the first try), it actually narrows the model’s overall reasoning coverage. The base model, given enough samples, can solve a wider range of problems than its RL-trained descendant. In contrast, distillation from a stronger teacher (like o1) is found to be the only current method that genuinely expands the reasoning boundary.
Literature Review
The paper situates itself within the rapid evolution of post-training for LLMs. While traditional instruction tuning (SFT) relies on human-curated data, RLVR has gained traction due to its scalability.
- Traditional RL (e.g., AlphaGo): Agents discover entirely new strategies through exploration.
- Current LLM RL (RLVR): Relies on policy gradient methods (like PPO or GRPO).
- Related Analysis: The authors build on recent observations that “reflective” behaviors (like “Wait, let me rethink…”) might already exist in base models. This paper provides the first systematic, quantitative proof using $pass@k$ across multiple domains (math, code, vision) that the base model serves as an upper bound for RL performance.
Methodology
The authors utilize several quantitative metrics and analytical frameworks:
- Metric - pass@k: To measure the “reasoning boundary,” they use an unbiased estimator: where $n$ is the total samples, and $c_i$ is the number of correct samples.
- Sampling Efficiency Gap ($\Delta_{SE}$): This measures how close an RL model’s first-try success ($pass@1$) is to the base model’s potential maximum ($pass@256$).
- Perplexity Analysis ($PPL$): To see if RL models generate “new” text, they calculate the likelihood of RL-generated paths under the base model’s distribution:
- Algorithms Evaluated: They tested six popular RL frameworks: PPO, GRPO, Reinforce++, RLOO, ReMax, and DAPO.
Experiment
The researchers conducted extensive tests across three main domains:
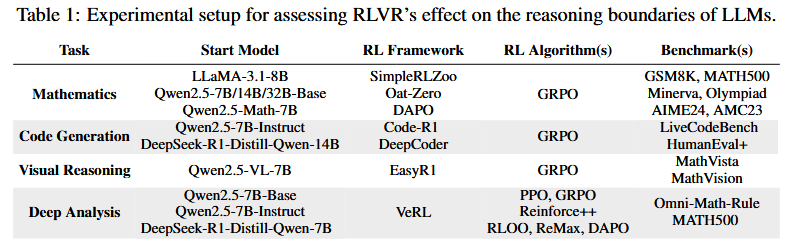
- Mathematics: Tested on AIME24, MATH500, and GSM8K using Qwen2.5 and LLaMA-3.1 models.
- Result: At $k=1$, RL models win. But at $k=1024$, the base model consistently surpasses the RL model. This proves the RL model “forgot” how to solve certain complex problems while focusing on easier ones.
- Code Generation: Evaluated on LiveCodeBench and HumanEval+.
- Result: Trends were identical to math. RL models showed a narrower “scope” of solvable problems compared to their base versions.
- Visual Reasoning: Evaluated on MathVista and MathVision.
- Result: Even in multimodal tasks, RLVR only sharpened existing patterns rather than creating new ones.
- Deep Analysis (The “Distillation” Difference):
- The authors compared RLVR against Distillation (e.g., DeepSeek-R1-Distill-Qwen).
- Finding: The distilled model’s $pass@k$ curve stays significantly above the base model’s curve even as $k$ increases. This indicates that knowledge transfer (SFT on high-quality CoT) genuinely expands a model’s capabilities, whereas self-improvement RL currently does not.
Final takeaway for developers: Current RL training is excellent for making models “reliable” and “fast” (improving $pass@1$), but to actually make a model “smarter” (expanding the boundary), we still need better data distillation or next-generation RL paradigms that incentivize true exploration.
Reference
[1] Y. Yue et al., “Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?,” presented at the The Thirty-ninth Annual Conference on Neural Information Processing Systems, Oct. 2025. Accessed: Dec. 11, 2025. [Online]. Available: https://openreview.net/forum?id=4OsgYD7em5