1000 layer networks for self Supervised rl scaling depth can enable new goal Reaching capabilities
Table of Contents
Source: “1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities” The Thirty-ninth Annual Conference on Neural Information Processing Systems
Introduction
Background
Scaling model size has been a highly effective recipe in many areas of machine learning, driven by breakthroughs in language and vision models like Llama 3 and Stable Diffusion. However, comparable progress in reinforcement learning (RL) has remained elusive, with most state-based RL tasks utilizing shallow architectures of only 2 to 5 layers. The primary difficulty stems from the sparse feedback in RL, where the ratio of reward signal to model parameters is extremely low. This work explores whether self-supervised RL building blocks can unlock scalability, focusing on network depth as a critical factor.
Objective
The primary objective of this research is to identify and study the building blocks that enable the scaling of reinforcement learning networks to much greater depths than previously explored. Specifically, the authors aim to demonstrate that increasing network depth (up to 1024 layers) can significantly boost performance in an unsupervised, goal-conditioned RL setting.
They focus on an environment where no demonstrations or external rewards are provided, requiring the agent to explore from scratch and learn to maximize the likelihood of reaching commanded goals. The goal is to show that scaling depth not only improves quantitative success rates but also leads to the emergence of qualitatively different and more capable behaviors, similar to the emergent phenomena observed in large-scale vision and language models.
Conclusion
The authors demonstrate that scaling network depth is a critical factor for performance in self-supervised RL. By using networks up to 1024 layers deep, they achieved 2x-50x performance gains on locomotion and manipulation tasks. Crucially, scaling depth leads to the emergence of qualitatively different behaviors (e.g., walking upright vs. falling) and allows the models to better leverage larger batch sizes and generalize through combinatorial stitching.
Literature Review
Achieving scaling advancements in reinforcement learning has been more challenging than in NLP and CV. Previous studies have identified several obstacles, including parameter underutilization, plasticity and capacity loss, data sparsity, and training instabilities. Consequently, current efforts to scale RL are often restricted to specific domains like imitation learning or multi-agent games.
Recent promising directions include new architectural paradigms, distributed training, and distributional RL. However, most contemporary works in this vein (e.g., Lee et al., 2024; Nauman et al., 2024b) primarily focus on increasing network width, noting limited gains from additional depth and typically using architectures with only four MLP layers. This work differentiates itself by showing that scaling along the axis of depth can be more powerful than scaling width alone. It also builds on the idea that classification-based objectives (like InfoNCE used in CRL) might be more robust and stable for scaling than traditional regression-based RL objectives.
Methodology
The core of the approach is the integration of ultra-deep neural networks with a self-supervised reinforcement learning framework.
1. Goal-Conditioned RL Framework
The authors define a goal-conditioned MDP as $M_g = (\mathcal{S}, \mathcal{A}, p_0, p, p_g, r_g, \gamma)$, where the reward function is defined as the probability density of reaching the goal in the next time step: The objective is to maximize the expected reward:
2. Contrastive RL (CRL) Algorithm
The method utilizes the Contrastive RL algorithm, an actor-critic method where the critic $f_{\phi,\psi}(s, a, g)$ is parameterized by two networks returning state-action pair embeddings $\phi(s, a)$ and goal embeddings $\psi(g)$. The critic’s output is the $l_2$-norm between these:
The critic is trained using the InfoNCE objective: where $g_i$ is a goal sampled from the same trajectory and $g_j$ are random negative goals. The policy $\pi_\theta(a|s,g)$ is then trained to maximize this critic:
3. Architectural Building Blocks for Depth
To enable scaling to 1024 layers, the architecture incorporates residual connections defined as: where $F_i$ consists of four repeated units of a Dense layer, Layer Normalization, and Swish activation. This setup ensures stable gradient propagation and allows the network to learn incremental modifications to representations rather than entirely new transformations. The network depth is defined as the total number of Dense layers across all residual blocks.
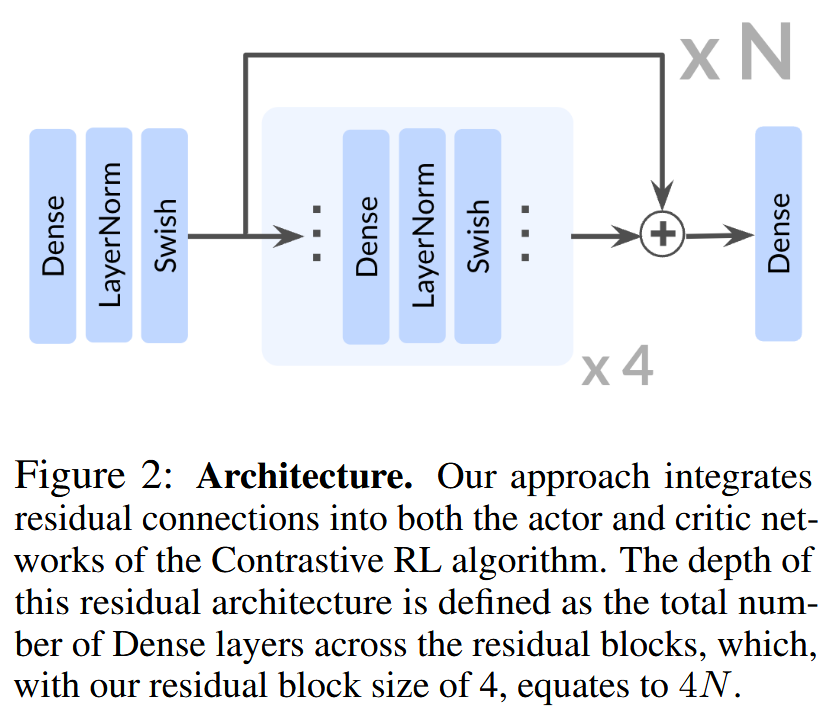
Experiment
Scaling network depth yielded substantial performance improvements across a suite of 10 environments. Compared to 4-layer baselines, deeper networks achieved 2-5x gains in robotic manipulation, over 20x gains in long-horizon maze tasks, and over 50x gains in humanoid tasks. Notably, the Humanoid Big Maze saw a staggering 1051x improvement. The results showed that performance often jumps at specific ‘critical depths’ (e.g., 16 layers for walking, 256 for vaulting over walls), corresponding to qualitatively distinct emergent policies.
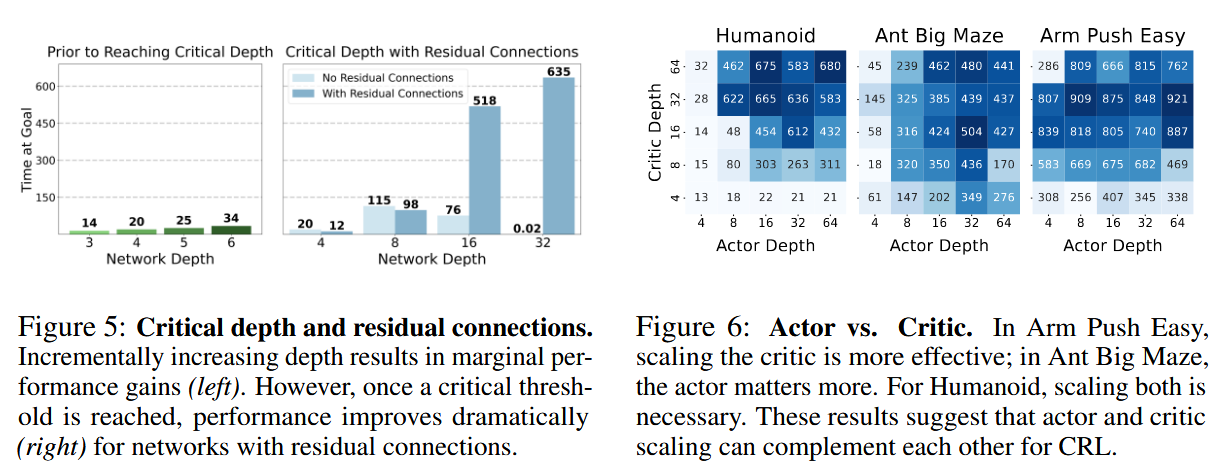
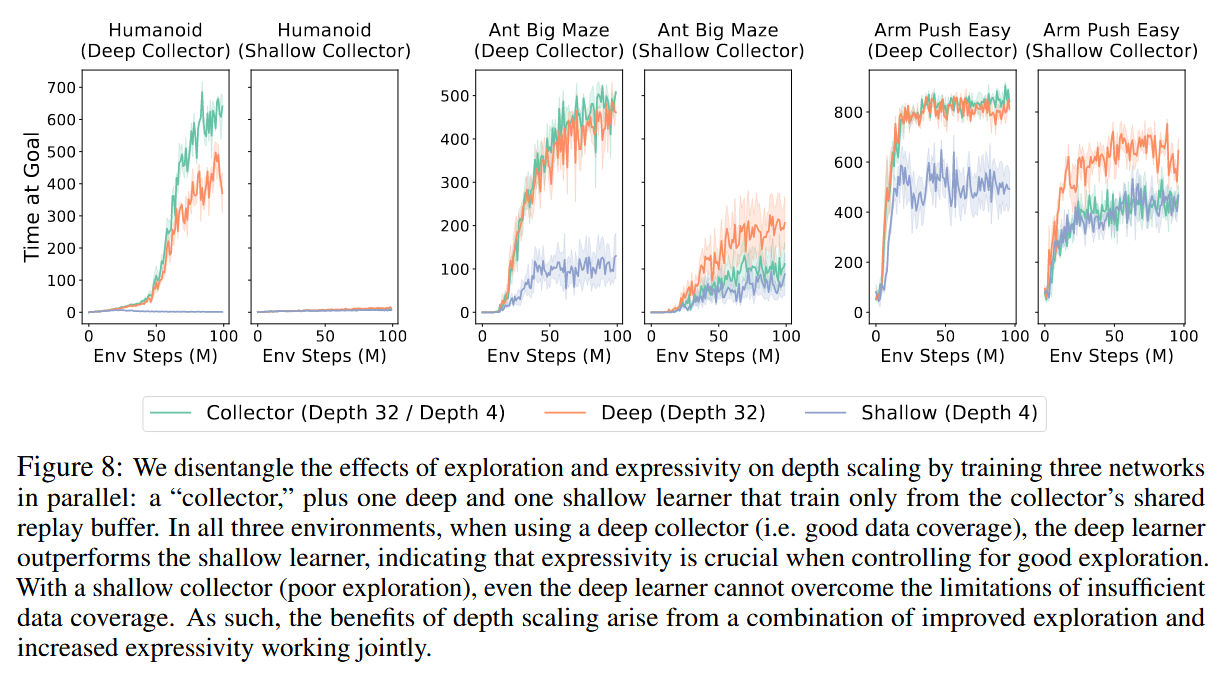
The authors also found that deeper networks unlock the benefits of larger batch sizes, which were previously reported to have negative impacts on shallower RL models. Additionally, deep networks demonstrated a superior ability for ‘combinatorial stitching,’ allowing agents to solve tasks by combining experiences from unseen start-goal pairs. A comparative analysis showed that depth scaling is uniquely effective for CRL; other standard RL algorithms like SAC and TD3+HER did not see similar benefits from depth, typically saturating or declining in performance beyond 4 layers. However, depth scaling was found to be less effective in offline settings, suggesting that the synergy between exploration and model capacity is vital.
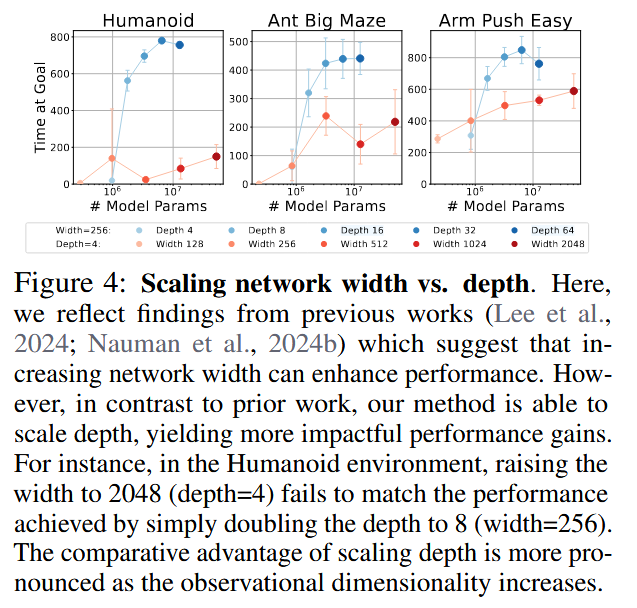
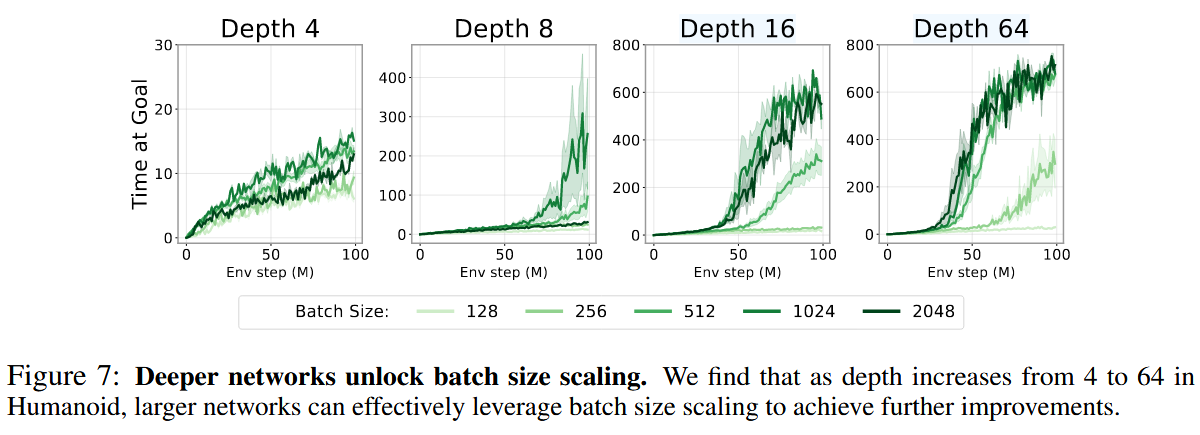
Reference
[1] K. Wang, I. Javali, M. Bortkiewicz, T. Trzcinski, and B. Eysenbach, “1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities,” presented at the The Thirty-ninth Annual Conference on Neural Information Processing Systems, Oct. 2025. Accessed: Dec. 11, 2025. [Online]. Available: https://openreview.net/forum?id=s0JVsx3bx1