Artificial hivemind the open Ended homogeneity of language models (and beyond)
Table of Contents
Source: “Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond),” The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track
Code: https://github.com/liweijiang/artificial-hivemind Dataset: INFINITY-CHAT Collection
Introduction
Background
Large language models (LLMs) are widely deployed as a personal creative assistant, yet they still failed in providing the diverse, human-like response for those open-minded questions. Prior evaluation benchmarks often focuses on stylized tasks (e.g. persona generation, storytelling, random number generation, etc.)
Objective
Introduce a new dataset with real-world open-minded queries
Conclusion
INFINITY-CHAT, a large-scale benchmark of 26K real-world open-ended user queries paired with diverse LM generations and dense human ratings, alongside a comprehensive taxonomy of open-ended prompt types (6 top-level, 17 subcategories) is introduced. Using this resource, we reveal a pronounced “Artificial Hivemind” effect:
- Strong intra-model repetition where individual LMs produce highly similar responses under high-stochasticity sampling
- Striking inter-model homogeneity where different model families converge on near-identical outputs.
Literature Review
Diversity collapse and mode collapse in LMs. Prior work has documented reduced output diversity in LMs and risks from training on synthetic or recursively generated data; alignment and post-training pipelines (e.g., RLHF) can further reduce conceptual variation. Several studies highlight potential societal harms from homogenized AI outputs, including diminished creative ideation and cultural narrowing.
Measuring creativity and divergent thinking. Benchmarks and tests adapted from psychometrics (DAT, AUT, TTCT) and bespoke creativity evaluations have been used to probe LMs’ divergent capabilities. While these approaches assess aspects of fluency, novelty, and semantic diversity, they often target stylized tasks and do not capture the breadth of real-world open-ended queries.
Pluralistic alignment and disagreement. Emerging research emphasizes pluralistic alignment—designing systems that accommodate heterogeneous human values and preferences—rather than enforcing single consensus objectives. Prior datasets and evaluation protocols typically use sparse annotations and assume a singular gold standard, limiting their ability to study distributional human preferences. Work on multi-model juries, model swarms, and diversity-aware training has proposed remedies but often lacks systematic, large-scale diagnostics in naturalistic open-ended settings.
Evaluation with LM judges and reward models. Using LMs as judges and learned reward models to score generations is widespread, but recent work shows limitations in calibration and reliability, particularly when annotator disagreement is high or when multiple responses are similarly high-quality.
Methodology
INFINITY-CHAT: Real-World Open-Ended Queries with Diverse Responses
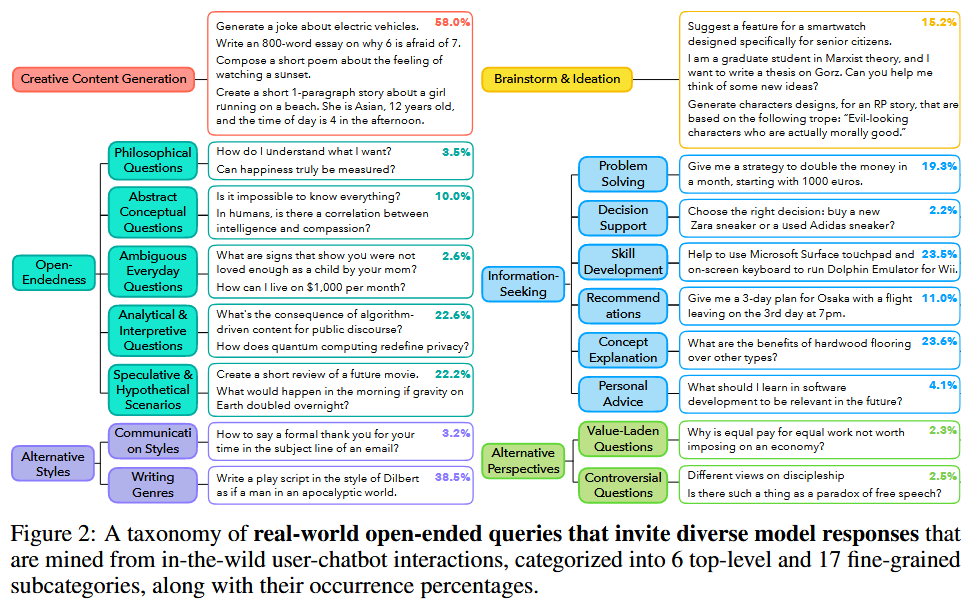
Mining in-the-wild open-ended user queries
INFINITY-CHAT is constructed by filtering and refining user input from WildChat for English, non-toxic, single-turn queries of length 15–200 characters, and used GPT-4o to classify queries along Meaningful Information, Greeting/Model Inquiry, and Response Type (single vs. multiple valid answers). After automatic cleaning and human refinement, 26,070 open-ended queries and 8,817 closed-ended queries is obtained.
Categorizing the diverse landscape of open-ended queries
Starting from ~100 seed queries manually labeled, a hierarchical taxonomy of open-ended prompts is built iteratively. GPT-4o is used to scale labeling over the full dataset, allowing multiple category assignments and detection of novel categories. The final taxonomy comprises 6 top-level categories and 17 fine-grained subcategories, validated with human annotation (human–model label agreement ≈74.7% on a validation subset).
Artificial Hivemind: Intra- and Inter-Model Homogeneity in LMs
Using a subset of INFINITY-CHAT (denoted INFINITYCHAT100), LLMs are examined on the “Artificial Hivemind” on two aspects: intra-model repetition and inter-model homogeneity.
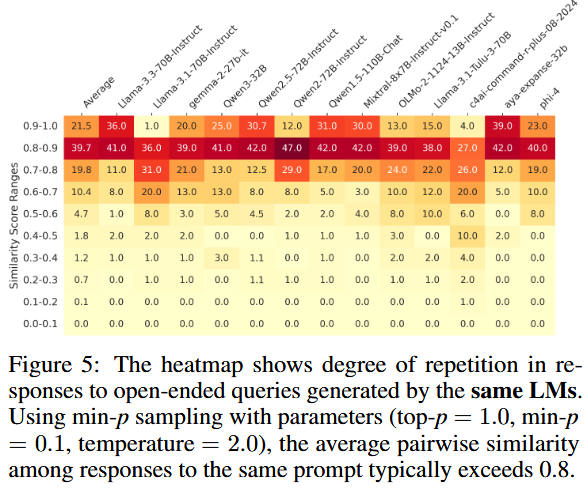
Intra-model repetition
50 responses per query sampled from INFINITYCHAT100 for each model, and the compute the average pairwise embeddings similarity. The settings used are $\text{top-p} = 0.9$, $\text{temperature} = 1$.
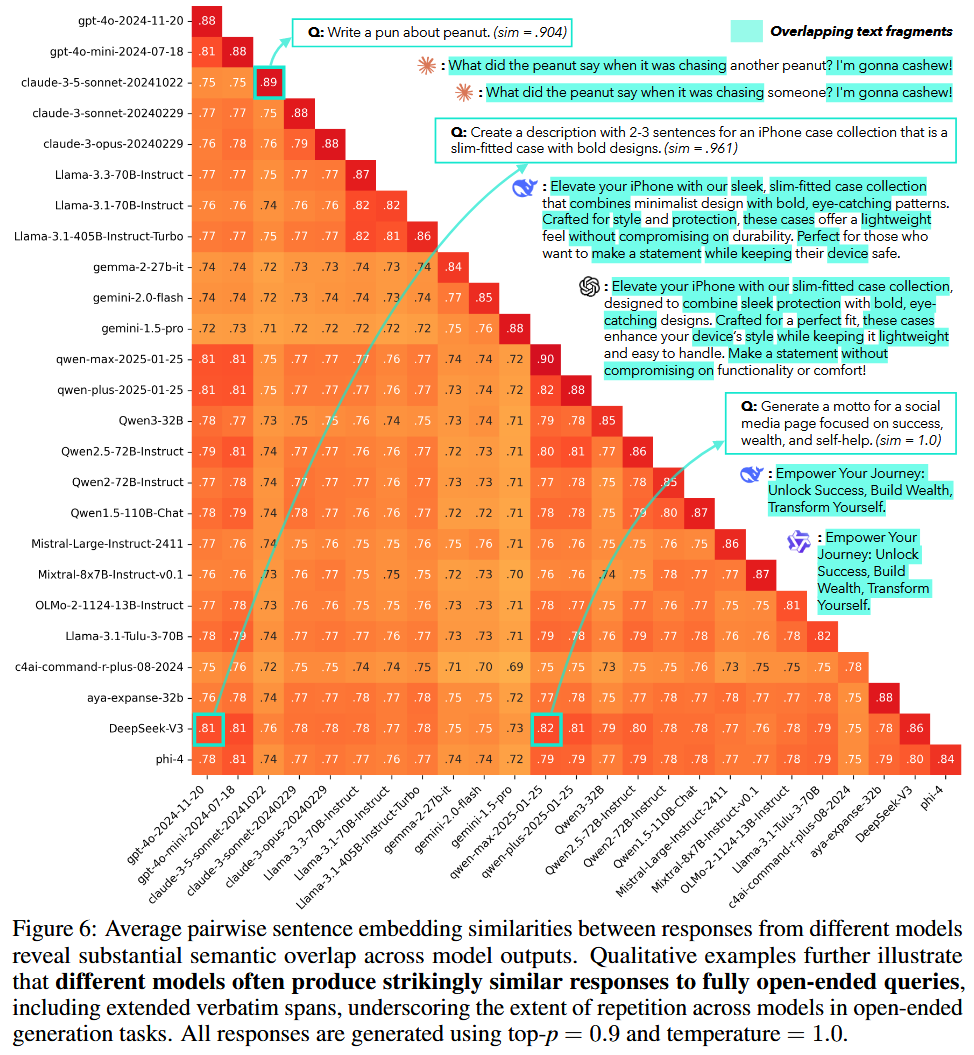
Inter-model homogeneity
Not only the same models will generate similar content repeating, models with different sizes or even family will also produce highly repetitive outputs (e.g. Deepseek V3 and Qwen-max share similarity of 82%)
Analysis
How Do LMs, Reward Models, and LM Judges Handle Alternative Responses to Open-Ended Queries?
Gathering Distributional Annotations Across Many Humans
To study the diversity of annotated dataset of different human preferences. Existing alignment dataset typically contain only sparse labels. Absolute ratings (1-5 scale) and pairwise preference ratings (strong/weak preference between two response to the same query).
Absolute ratings: Sampled 15 responses each for 50 prompts from INFINITYCHAT100 and 25 ratings per response Pairwise preference rating: Sampled 10 response pairs per prompt and gathered 25 annotations per response.
Gathering LMs, Reward Models, and LM Judges Ratings
The alignment of LMs, reward models and LM judges with human ratings are evaluated with the open-ended ratings.
- LM scores are derived from response perplexity given the query
- Reward model scores are based on standardized scalar reward outputs
- LM judge ratings follow standard prompting protocols using two rubrics: an overall quality score and the HHH rubric (Helpfulness, Harmlessness, Honesty)
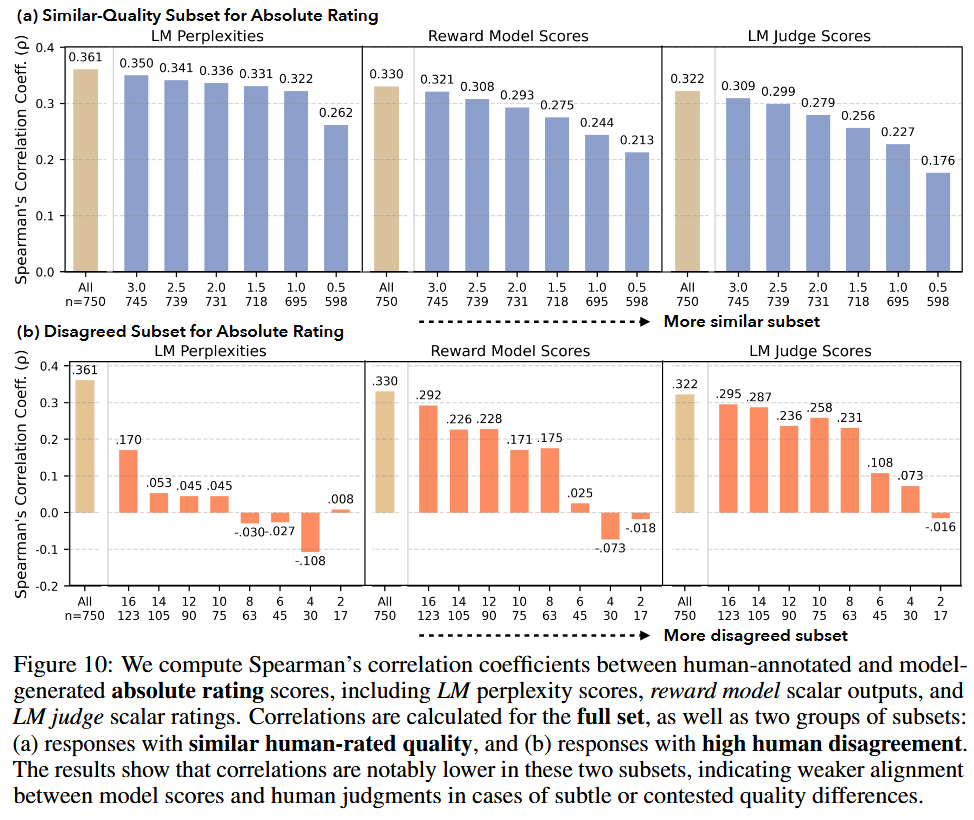
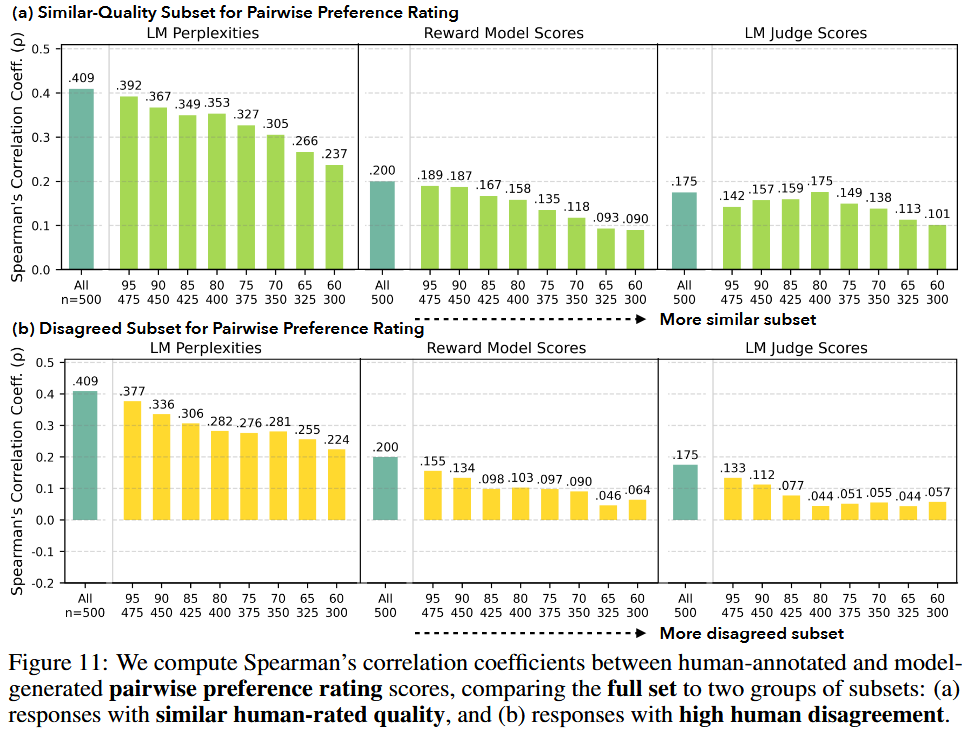
Comparing Model Ratings to Human Scores for Responses to Open-Ended Queries
- Motivation for comparing model scores to average human ratings
- Models show weaker alignment with human ratings for alternative responses of similar quality
- Model judgments are less aligned where annotators disagree
Reference
[1] L. Jiang et al., “Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond),” presented at the The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, Oct. 2025. Accessed: Dec. 11, 2025. [Online]. Available: https://openreview.net/forum?id=saDOrrnNTz