Gated attention for large language models non Linearity, sparsity, and attention Sink Free
Table of Contents
Source: “Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free,” The Thirty-ninth Annual Conference on Neural Information Processing Systems
Introduction
Background
Gating mechanism is widely used in neural network since early models like LSTM and Highway Networks to control the information loss across time steps or layers. This extends to modern architectures such as state spaces models, linear models and softmax attention.
Despite the prevalence, the specific effects of gating in attention mechanism have not been thoroughly investigated. Existing works often confound gating with other architectural changes, hindering understanding of its intrinsic value.
Objective
Systematically investigate gating mechanism in softmax attention for large language models and to introduce methods to make use of the intrinsic value from gating mechanism
Conclusion
The authors demonstrate that applying a head-specific sigmoid gate after the Scaled Dot-Product Attention (SDPA) output consistently improves LLM performance, with up to 0.2 PPL reduction and 2 points on MMLU. This gating enhances training stability, tolerates larger learning rates, and improves scaling properties. The effectiveness stems from introducing non-linearity to the low-rank attention mapping and applying query-dependent sparse gating scores, which mitigate massive activations and attention sinks. Notably, gated models exhibit superior long-context performance, gaining over 10 points on RULER. The most effective SDPA output gating is used in the Qwen3-Next models, and the authors release codes and models for future research.
Literature Review
Gating in Neural Networks
Gating mechanism has been fundamental in neural networks since LSTM, Highway Networks and GRU, controlling the information flow. Modern works incorporates gating in stat-space models, linear attention and softmax attention. However, most studies do not isolate gating’s effects. For instance, Switch Heads uses gating for expert selection, but experiments show gating alone provides value. Quantizable Transformer uses gating to reduce outliers in BERT/ViT.
Attention Sink
StreamingLLM formally defines ‘Attention Sink’ where specific tokens receive large attention scores. Some redundant tokens act as ‘registers’ to store attention scores in ViT. In Massive Activation, the excessive attention scores are assigned to tokens associated with massive activation values.
Methodology
Symbol Notation:
- $Y$ : The input to be modulated
- $X$ : Input to used to compute gating scores
- $W_\theta$ : Learnable parameter of gate
- $\sigma$ : Activation function
- $Y’$ : Gated output
- $\sigma(XW_\theta)$ : Gating score
Augmentation of Softmax Attention with Gating Mechanism
The gating mechanism is formalized as:
Experiment
Experiments Setup
Models (GQA in attention):
- MoE models (15A2B, 128 experts, Top-8, Fine-grained experts, Global batch LBL, Z-loss)
- Warmups at max LR of 2e-3 in 1k steps and decay using cosine to 3e-5
- Global batch size of 1024 comprising 100k optimization steps
- Dense models (1.7B)
- 400 tokens with max LR of 4e-3 and batch size 1024
- 3.5T tokens training with max LR of 4.5e-3 and batch size 2048
Dataset:
- Training: 4T multilingual, math, general knowledge content. 4096 Sequence length
- Evaluation: Hellaswag, MMLU, GSM8k, HumanEval, C-val, CMMLU
Ablation Experiments
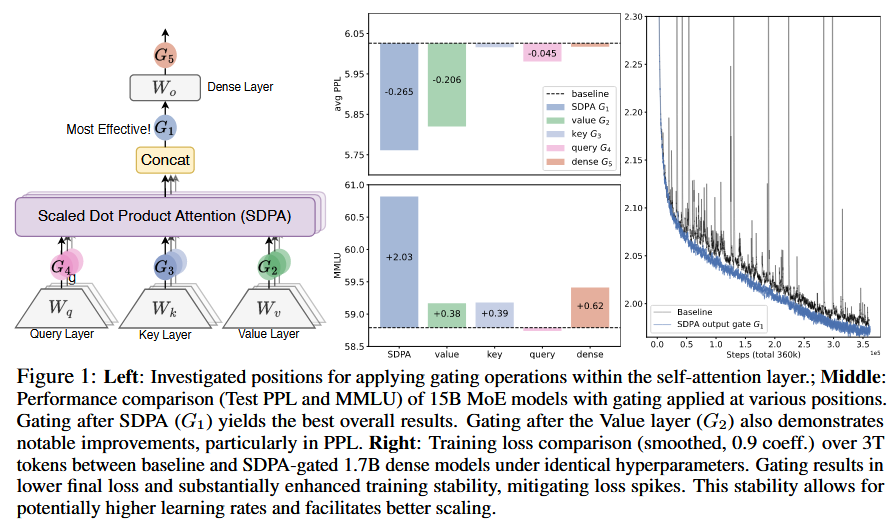
- Positions: After QKV positions, After SDPA
- Granularity: Headwise (single scalar), Elementwise (vector)
- Head specific or shared: Specific (Independent scores), Shared
- Multiplicative or additive: $Y’=Y\odot \sigma(X\theta)$, $Y’=Y+ \sigma(X\theta)$
- Activation function: SiLU, Sigmoid
MoE Model Results
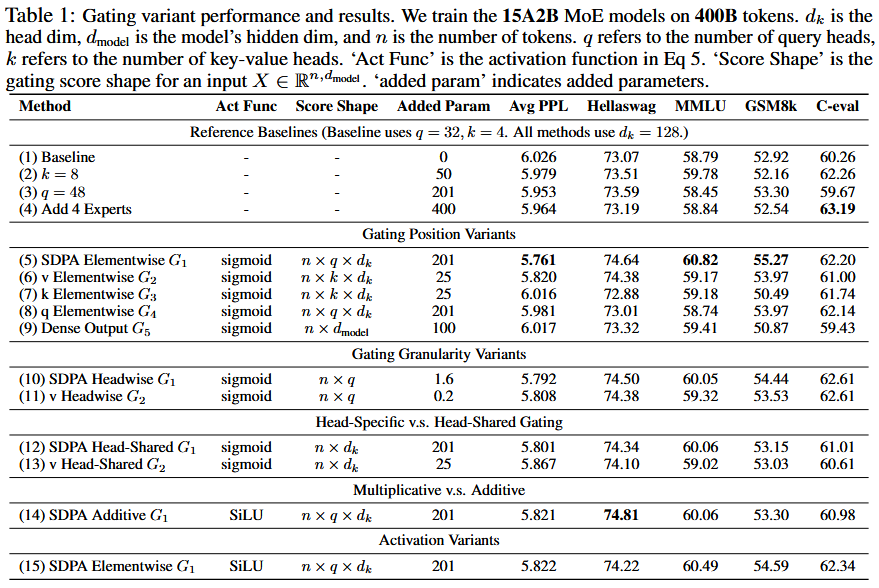
- Positions: $G_1$ & $G_2$
- Head specific or shared: Head specific
- Multiplicative or additive: $Y’=Y\odot \sigma(X\theta)$
- Activation function: Sigmoid
Dense Model Results
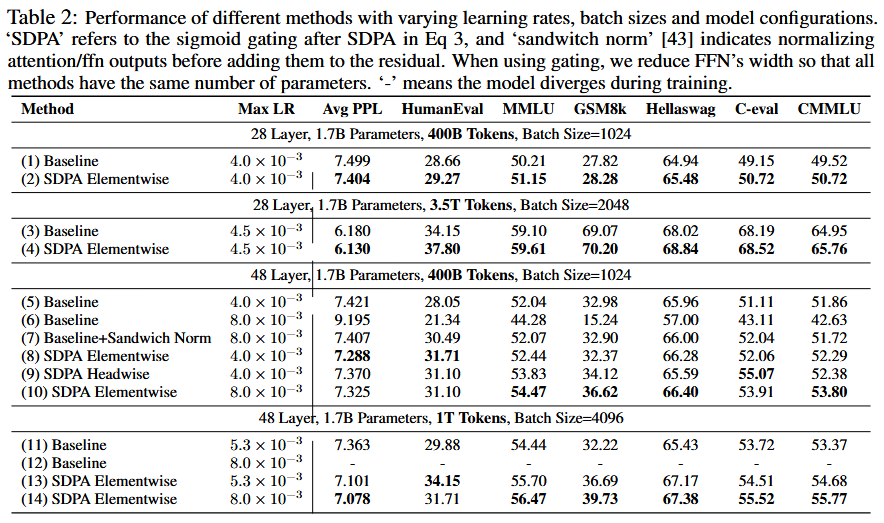
- Positions: Effective over all settings
- Gating improves stability and facilitates scaling
Analysis
Non-linearity Improves the Expressiveness of Low-Rank Mapping in Attention
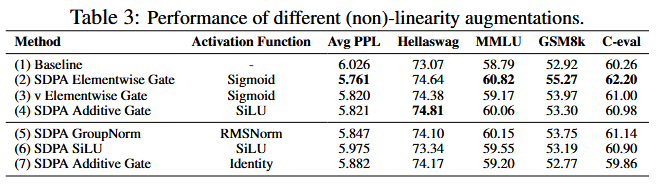
From the results in table above, given that adding non-linearity between two linear mappings can improve their expensiveness, two modifications are provided to mitigate the low-rank problem:
This is applied to $G_2$ position
This added gating or group normalization at position $G_1$.
In summary, the introduction to non-linearity in $W_V$ and $W_O$ enhance the performance
Gating Introduces Input-Dependent Sparsity
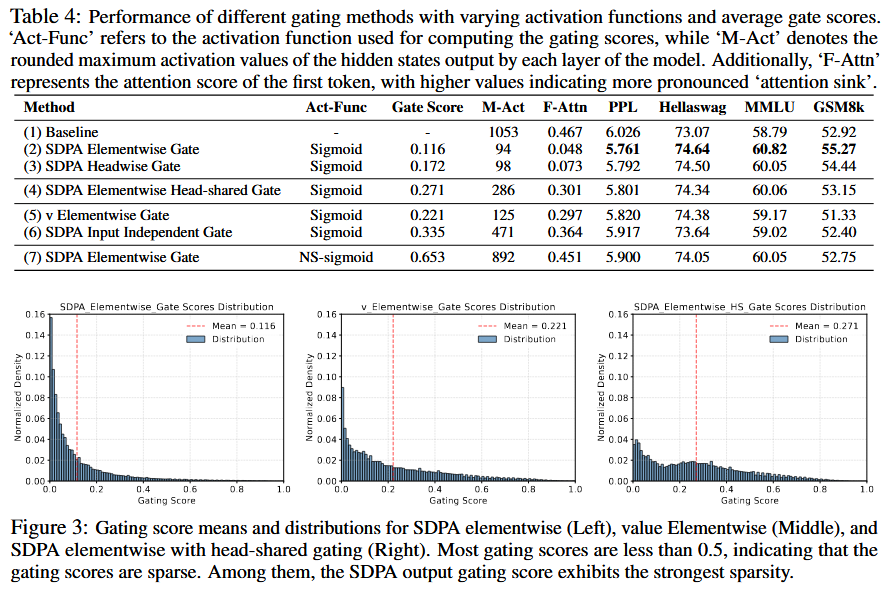
Key observations:
- Effective Gating Scores are Sparse
- Head-Specific Sparsity Matters
- Query-Dependency Matters: Q >KV. “gating score sparsity may filter out irrelevant contextual information for the query”
- Less Sparse Gating is Worse
SDPA Output Gating Reduces Massive Activation and Attention-Sink
Key observations:
- Head-wise and element-wise query-dependent sigmoid gating at G1 largely reduces the attention score allocated to the first token and decreases massive activations.
- Enforcing shared gating scores across heads or applying gating only at G2 decreases massive activations, but does not reduce attention scores to the first token. This reinforces the importance of head-specific gating and suggests that massive activations are not a necessary condition for attention sinks.
- Reducing the input-dependence of gating or using NS-sigmoid to reduce sparsity intensifies both massive activations and attention sink.
This may explain the improved training stability with gating: by reducing massive activations, the model is less susceptible to numerical errors during BF16 training
SDPA Output Gating Facilitates Context Length Extension
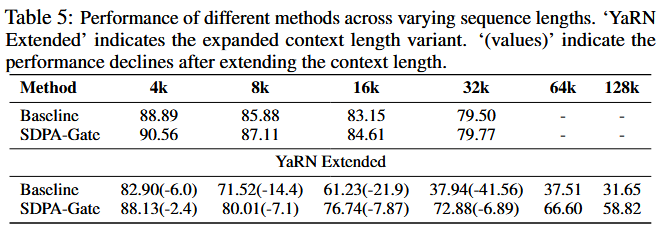
Key observations:
- Under the 32k setting, models with gating slightly outperform the baseline. This suggests that within the training length, the attention sink phenomenon may not hurt the model’s long-context performance.
- When the context length is extended to 128k using YaRN, both the baseline and gated models experience a decline within the original 32k range. This observation is consistent with previous works on extending context length by modifying RoPE.
- At context lengths of 64k and 128k, the gated attention models outperform the baseline signifantly.
Possible explanation: Baseline models rely on attention sinks to adjust the distribution of attention scores
Reference
[1] Z. Qiu et al., “Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free,” presented at the The Thirty-ninth Annual Conference on Neural Information Processing Systems, Oct. 2025. Accessed: Dec. 11, 2025. [Online]. Available: https://openreview.net/forum?id=1b7whO4SfY