Lightmem Lightweight and efficient memory Augmented generation
Table of Contents
Source: “LightMem: Lightweight and Efficient Memory-Augmented Generation,” arXiv: arXiv:2510.18866
Introduction
Background
Memory is the fundamental to intelligent system to obtain prior experience/contextual cues/task-specific knowledge in order to perform robust reasoning/decision-making.
Large language models (LLMs) demonstrate remarkable capabilities in various tasks but they often have limitations on long-context or multi-turn interaction scenarios due to fixed context length and “lost in the middle” problem.
Memory systems is one of the solution to overcome this problem for LLMs by maintaining a persistent state across extended interactions. It processes raw interaction data as manageable chunks, organizes them into long-term memory by indexing them into memory units and continuously updating by adding new information and discarding outdating/conflicting content.
Contemporary memory systems still suffer from:
- Redundant information from user input and model responses in long interactions will affect the model construction
- Memory construction treats every input by turns or context window causing failure to build semantic connections across turns.
- Memory updates are usually performed during inference which introduces long test-time latency in long-horizon tasks and prevents deeper, reflective processing of past experiences.
Objective
Develop a lightweight memory architecture to address three key limitations:
- Redundant sensory memory
- Balancing effectiveness and efficiency in short-term memory
- Inefficient long-term memory updating
Conclusion
LightMem successfully introduces a lightweight and efficient memory framework designed to address the significant overhead of memory systems for LLM agents. By drawing inspiration from the multi-stage Atkinson-Shiffrin human memory model, the architecture effectively filters, organizes, and consolidates information through three complementary stages.
The empirical evaluation on LongMemEval demonstrates that LightMem achieves superior performance across multiple dimensions:
- Accuracy: Outperforms the strongest baseline (A-MEM) by 2.70%–9.65% in QA accuracy with GPT backbone and up to 7.67% with Qwen backbone
- Token Efficiency: Reduces token usage by 32×–117× compared to memory baselines
- API Call Reduction: Decreases API calls by 17×–177× for GPT and 19×–177× for Qwen
- Runtime Improvement: Achieves 1.67×–12.45× faster execution
The offline “sleep-time” consolidation mechanism enables more reliable long-term knowledge updates, mitigating information loss and inconsistency in extended interactions. Case studies reveal that soft updates preserve global information and complete semantics by performing only incremental additions during test time, avoiding the irreversible information loss that can occur with hard updates.
The authors outline several promising future directions including: offline update acceleration using pre-computed KV caches, knowledge graph-based memory for multi-hop reasoning, multimodal memory extension for embodied agents, and exploration of parametric-nonparametric synergy for more flexible knowledge utilization.
Literature Review
Hard Prompt Compression for LLMs: Improves LLM efficiency by removing redundant content from prompts. This method is recently proven in small language models (SLMs) to query aware approaches that preserves task-relevant information.
Chunking Strategies in RAG Systems: Retrieval-Augmented Generation (RAG) systems rely on chunking external documents into smaller units for retrieval. Existing chunking strategies include:
- Rule-based methods creating fixed-size segments
- Semantic-based methods grouping content by topic
- LLM-driven methods leveraging model knowledge for splitting But these methods are tailored to static scenarios, not applicable to dynamic and open-ended environments
Memory Systems for LLM Agents: Memory systems help LLM agents move beyond stateless interactions to support flexible reasoning in complex environments. The evolution includes:
- Sequential/Hierarchical Storage: Early approaches store experiences as linear streams, sometimes enhanced with hierarchical structures (SCM, Generative Agents, MemGPT, MemoryBank)
- Structured Representations: More recent methods represent memories as nodes and relationships using trees, graphs, or temporal knowledge structures (Mem0, A-MEM, Zep)
- Multi-Type Integration: The latest trend integrates various memory types to interact synergistically (MemoryOS, MEMOS, Mirix, Nemori)
The authors note that while existing memory systems have become increasingly complex and capable, most focus on maximizing effectiveness with limited consideration of efficiency. Some recent works like LightRAG and E²GraphRAG share similar efficiency motivations but focus on static corpus scenarios rather than dynamic conversational settings.
Methodology
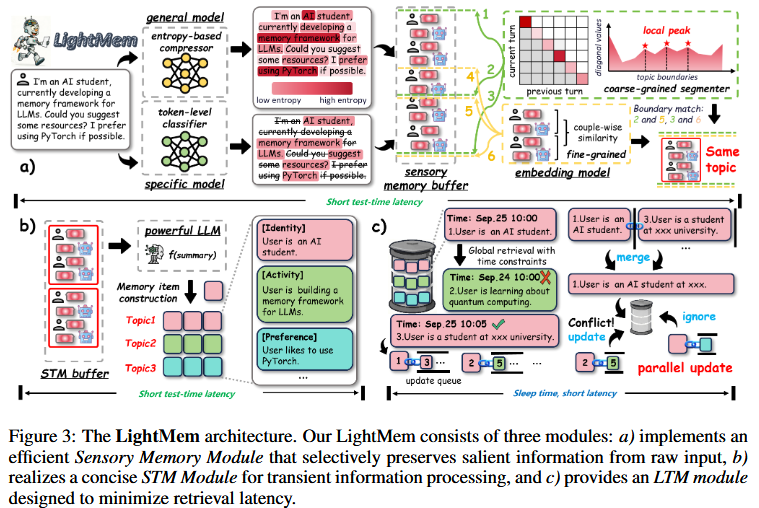
LightMem is designed as a three-module architecture analogous to human memory, consisting of Light1 (Sensory memory), Light2 (Short-term memory), Light3 (Long-term memory)
Symbols Notation
- $x$ : raw input tokens
- $\theta$ : model
- $r$ : compression ratio
- $q(x_i)$ : true token label distribution
- $\text{sim}(\cdot,\cdot)$ : similarity function
Light1: Cognitive-inspired sensory memory
Pre-Compressing Submodule
This module leverages a compression model $\theta$ to eliminate the large portion of redundant tokens in long horizon interaction scenarios:
here uses LLMLingua-2 as the compression model. The threshold $\tau$ is set to the $r$-th percentile of retention scores, keeping only tokens above $\tau$. $P(\text{retain }x_i\mid x)$ is a binary token classification task (“retain” or “discard”). For each token $x_i$ in a sequence $x$, the model $\theta$ outputs a logit vector $\ell_i$, and the retention probability is given by:
where the subscript $1$ denotes the “retain” class.
A token filtering mechanism is implemented with cross-entropy between the model’s logits and the true token labels:
Tokens with higher conditional entropy under a given context are more uncertain and less predictable, indicating greater informational uniqueness and a more critical role in semantic expression, such distinctive tokens are essential for subsequent memory construction and are therefore retained.
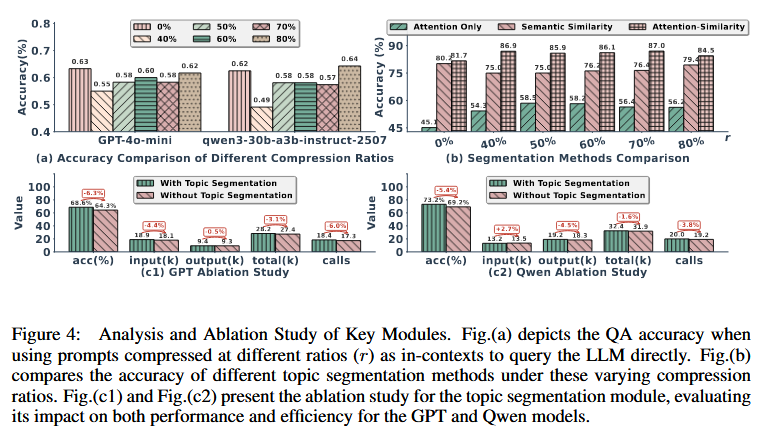
Topic Segmentation Submodule
LightMem maintains a sensory memory buffer to temporarily store information after precompression. When the accumulated information reaches the buffer’s maximum capacity, a hybrid topic segmentation operation based on attention and similarity is triggered.
The final segmentation boundaries as the intersection of attention-based boundaries $\mathcal{B}_1$ and similarity-based boundaries $\mathcal{B}_2$ :
Light2: Topic-aware short-term memory
After obtaining individual topic segments, LightMem forms an index structure {topic,turns}, where turns={user,model}. These are placed into the short-term memory (STM) buffer. When the buffer exceeds the preset threshold, the LLM $f_\text{sum}$ generates concise summaries of every structure. The final index structure stored in long-term memory (LTM) is {topic, {sum,user,model}}
where $\text{Entry}_i$ denotes the memory entry to be stored in LTM. Feeding multiple can reduce the API calls and increase the accuracy comparing to single turn.
Light3: Long-term memory with sleep-time update
Soft updating at test time
LightMem inserts all the memory in LTM with soft updates, then decouple the update process from online inference at test time.
where $e_i$ denotes the $i$-th memory entry with embeddings $v_i$ and timestamp $t_i$, $\text{Top}k{\cdot}$ indicates selecting the top-$k$ most similar candidates, with the update queue $\mathcal{Q}(e_i)$ length fixed at $n$.
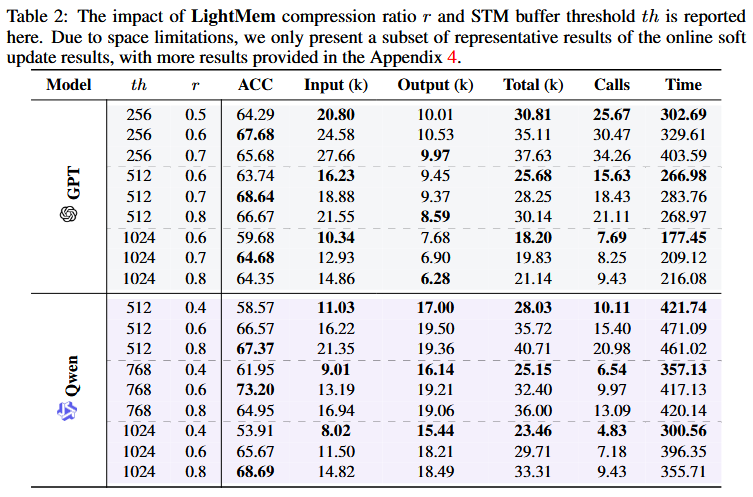
Experiment
Dataset:
- LongMemEval-S (500 dialogue histories, each with an average of 50 sessions and 110K tokens)
Models:
- GPT-4o Mini
- Qwen3-30B-A3B-Instruct-2507
Reference
[1] J. Fang et al., “LightMem: Lightweight and Efficient Memory-Augmented Generation,” Oct. 21, 2025, arXiv: arXiv:2510.18866. doi: 10.48550/arXiv.2510.18866.