Inside vllm how this amazing engine makes large models lightning fast
Table of Contents
Source: Inside vLLM: Anatomy of a High-Throughput LLM Inference System - Aleksa Gordić
🚀 Supercharging AI: A Simple Guide to How vLLM Works
Have you ever wondered how big AI models like Llama or Mistral can talk to thousands of people at once without slowing down? The secret is a highly specialized engine called vLLM (Vectorized Large Language Model), designed to make AI inference lightning fast!
Think of vLLM as the pit crew for a Formula 1 race car (the LLM). It doesn’t build the car, but it makes sure every stop, every tire change, and every refuel is done with maximum speed and zero wasted time.
1. The Core Concept: High-Throughput Inference
The main goal of vLLM is high-throughput. This just means processing the maximum number of requests (or users) per second.
vLLM achieves this by managing three core areas inside its LLM Engine:
- Memory: How it stores the AI’s internal scratchpad.
- Scheduling: Deciding which user’s turn it is.
- Execution: Running the math on the GPU.
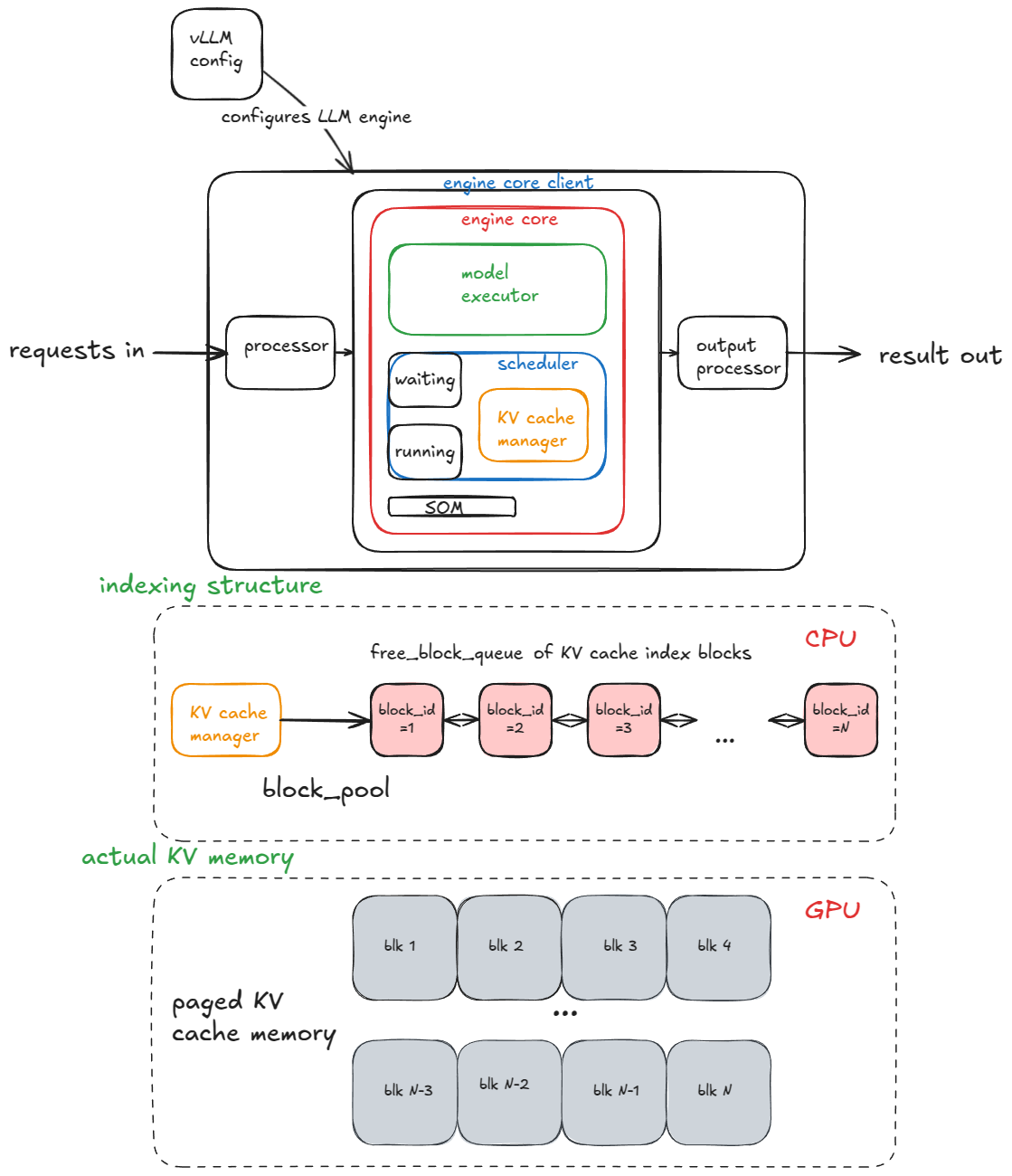
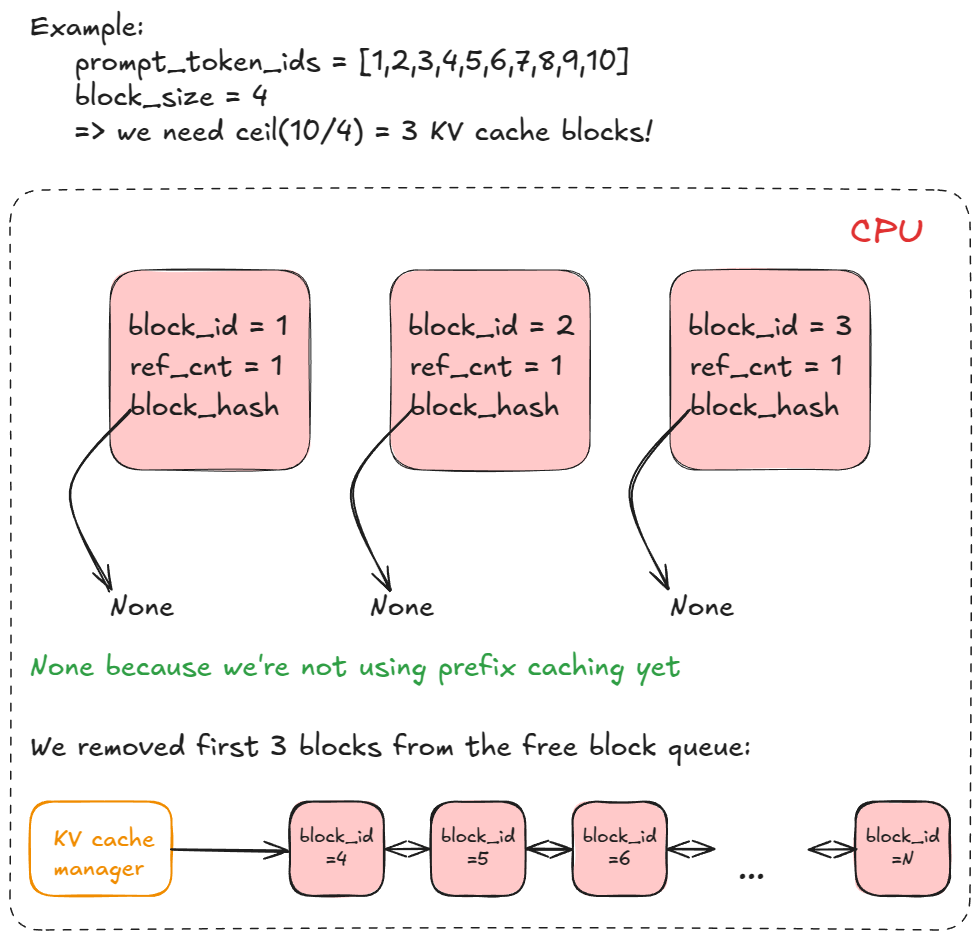
2. Working Principle A: Paged Attention (The Smart Memory Manager)
To generate text, an LLM constantly uses a piece of information called the KV Cache (Key and Value Cache). This is like the model’s short-term memory of everything it has said so far in the conversation.
The Old Way (Wasting Space)
Traditionally, systems reserve a single, giant, contiguous block of memory for a request, assuming the user might write a 4,000-word essay. If the user only writes a few sentences, all that reserved memory sits empty—it’s wasted space.
The vLLM Way (Paged Attention)
vLLM borrowed an idea from computer operating systems called paging.
- It breaks the KV Cache memory into small, fixed-size blocks (like small, reusable parking spots).
- A request’s memory doesn’t have to be one long chunk; its blocks can be scattered anywhere in the GPU’s memory pool.
- A Block Table acts like a map, telling the system exactly which parking spots belong to which user.
This prevents wasted memory and allows vLLM to squeeze far more users onto the same GPU.
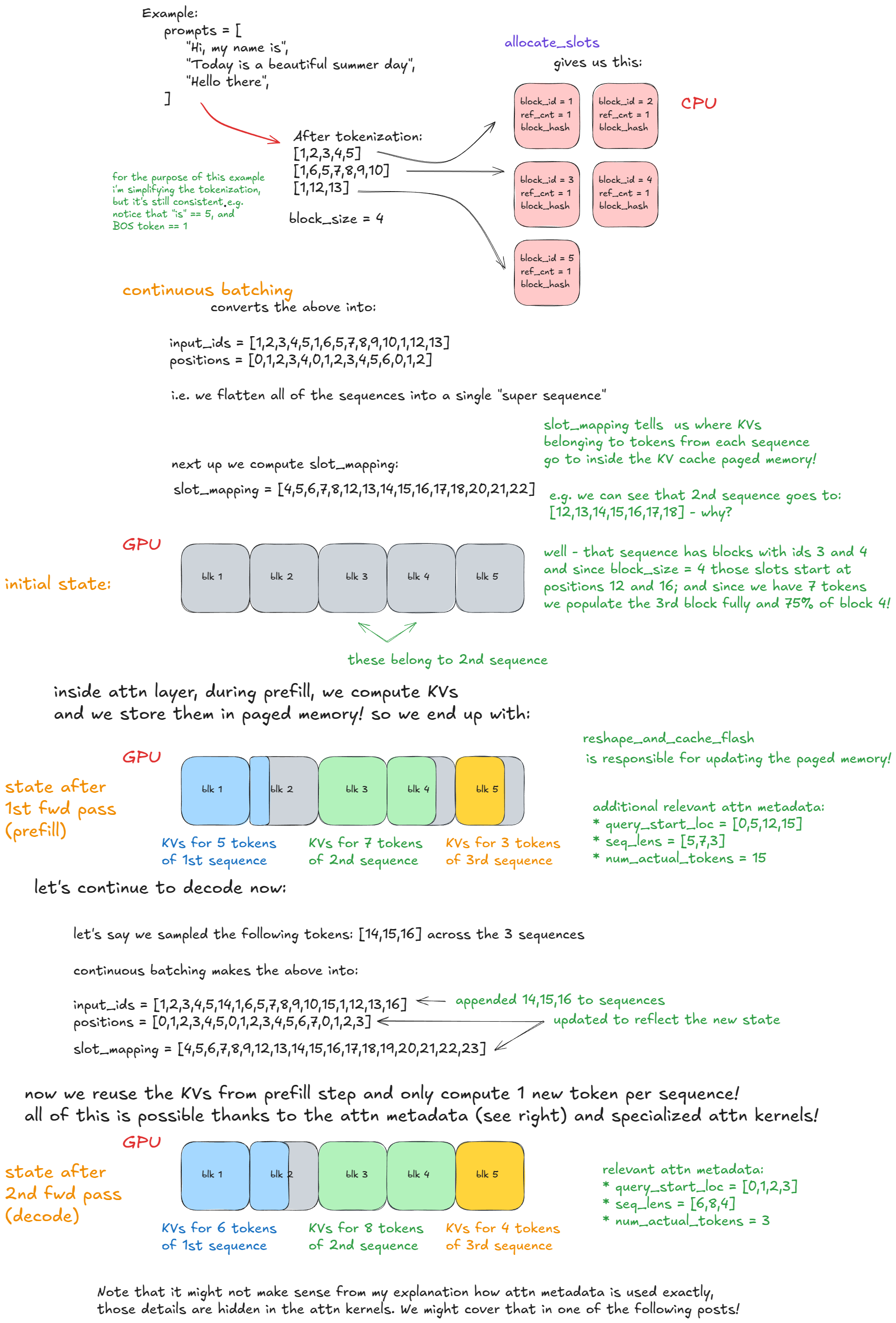
3. Working Principle B: Continuous Batching (The Non-Stop Scheduler)
When you ask an AI a question, the process has two parts:
- Prefill: Reading and processing your initial, long prompt (a big math job).
- Decode: Generating the new answer token-by-token (a quick back-and-forth job).
The Old Way (Waiting in Line)
Old systems often waited for a whole batch of Prefill requests to finish generating their first token before they allowed new requests to start. This leaves the super-powerful GPU waiting around.
The vLLM Way (Continuous Batching)
vLLM uses a smart Scheduler that never lets the GPU rest.
- After every single token is generated, the scheduler instantly looks at the queue and creates a new batch.
- This new batch often mixes Decode (ongoing answers) and new Prefill (new questions) requests together.
- It combines all these requests into one giant “super-sequence” and sends it to the GPU in a single forward pass.
This non-stop, dynamic process ensures the GPU is always running at its peak, leading to massive gains in throughput.
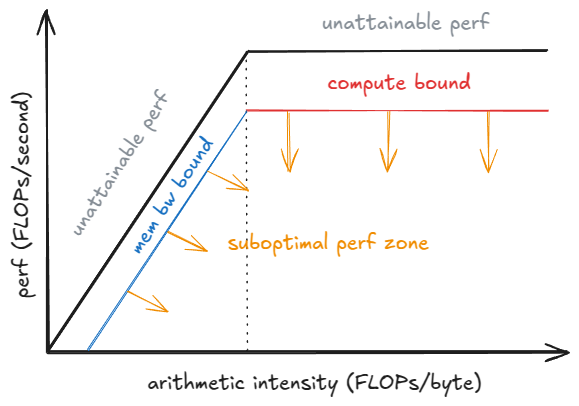
4. The Performance Secret: Why It’s Faster
Ultimately, vLLM’s techniques shift the bottleneck of AI inference.
The speed of an LLM is usually limited by either:
- Memory Bandwidth: How fast the data can move from memory to the processor.
- Compute: How fast the processor can do the math.
By using Paged Attention to save memory and Continuous Batching to fill up the GPU with useful work, vLLM makes it possible to run larger batches. Running a larger batch means the GPU spends less time waiting for data and more time doing the actual math, pushing the system away from the slower memory limit toward the much faster compute limit.
🙏 Acknowledgement / Source
This detailed breakdown and analysis of vLLM’s architecture, including the core concepts of Paged Attention and Continuous Batching, is based entirely on the excellent article: “Inside vLLM: Anatomy of a High-Throughput LLM Inference System” by Aleksa Gordić at https://www.aleksagordic.com/blog/vllm.
All credit for the technical diagrams and detailed analysis goes to the original author.