Brillm Brain Inspired Large Language Model
Table of Contents
Source: “BriLLM: Brain-inspired Large Language Model,” arXiv: arXiv:2503.11299
Introduction
Background
Bottlenecks of Artificial General Intelligence (AGI):
- Disconnection between language models and world models
- Limitations of Transformer-based architectures in conventional representation learning
True AGI must encompass the complete “perception–thinking & decision-making–action” cognitive chain, requiring both embodiment and multimodality.
Current large language models (LLM) and world models cannot achieve human-level AGI. Human brain still remains as the only empirically validated system capable of using limited perceptual modalities to indirectly comprehend unexperienceable concepts through abstract conceptualization. Current models lack this cross-modal indirect cognition and abstract creation capability.
The fundamental barrier lies in the representation learning paradigm underpinning all modern Machine Learning (ML) and Deep Learning (DL) systems, including Transformers/GPT architectures. While Transformers represent the state-of-the-art, they inherit intrinsic flaws: black-box opacity (only inputs/outputs are interpretable) and quadratic computational complexity (due to attention mechanisms scaling with sequence length). These are paradigm-level constraints inherent to the vector shape-based foundation of representation learning.
Objective
Develop the first macroscopically brain-inspired Large Language Model using Signal Fully-connected flowing (SiFu) learning - a non-representation learning paradigm that instantiates brain-inspired macroscopic properties and Occam’s Razor simplicity.
Conclusion
BriLLM and its underlying SiFu learning paradigm represent a fundamental departure from representation learning—the foundation of all contemporary ML/DL systems. By implementing two brain-inspired principles—static semantic mapping to nodes (analogous to cortical regions) and dynamic signal propagation (analogous to EEG activity)—BriLLM achieves three transformative capabilities absent in current LLMs: full node-level interpretability, context-length-independent scaling, and global-scale simulation of brain-like processing.
The 1-2B parameter models validate the SiFu paradigm by replicating GPT-1’s core generative capability (sequence continuation) with stable learning dynamics. The architecture enables natural multi-modal compatibility, full model interpretability at the node level, and context-length independent scaling. Sparse training reduces parameters by 87-94%, demonstrating efficiency akin to the brain’s sparse connectivity.
The paradigm is reinforced by both Occam’s Razor—evidenced in the simplicity of direct semantic mapping—and natural evolution—given the brain’s empirically validated AGI architecture. BriLLM establishes a novel, biologically grounded framework for AGI advancement that addresses fundamental limitations of current approaches, positioning itself as an indispensable core component for constructing sophisticated AGI systems.
Methodology
SiFu Mechanism
The Signal Fully-connected flowing (SiFu) learning paradigm is built on two neurocognitive principles:
- Static semantic mapping: Tokens are mapped to specialized nodes analogous to cortical areas
- Dynamic signal propagation: Simulates electrophysiological information dynamics observed in brain activity
SiFu models semantic processing as a fully-connected directed graph $G = {V,E}$ where:
- $V = {v_1,v_2,…,v_n}$ : A set of nodes with each $v_i$ uniquely mapping to a semantic unit (e.g. text token)
- $E = {e_{ij} \mid i,j\in{1,…,n}}$ : A set of directed edges, where $e_{ij}$ governs a signal transmission from $v_i$ to $v_j$.
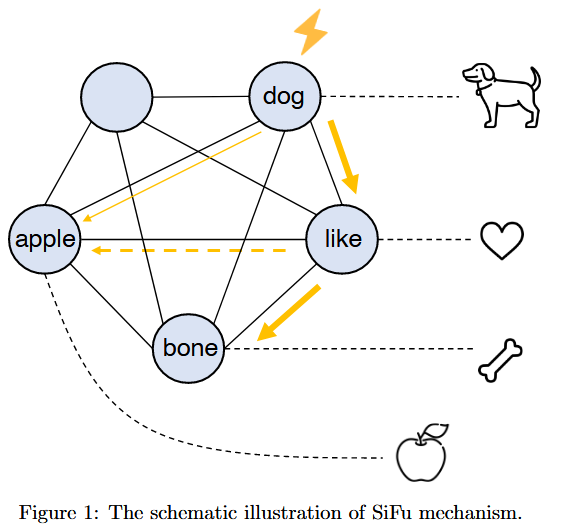
A signal tensor $r \in \mathbb{R}^{d_\text{node}}$ measures the “activity level” of a node. Signals initiate at input token nodes, propagate through edges, and undergo transformations via node-wise (⊕) and edge-wise (⊗) operations.
BriLLM Architecture
Three biologically inspired assumptions:
- Node design: Each node models a ‘cortical region’ implemented as a GeLU-activated layer with bias $b\in\mathbb{R}^{d_\text{node}}$
- Edge design: Edges are bidirectional with weight matrices $W_{u,v}, W_{v,u} \in \mathbb{R}^{d_\text{node}\times d_\text{node}}$
- Positional Encoding: Sine-cosine positional encoding preserves sequence order
Signal Propagation
For sequence $v1, v2, …, v_{L-1}$, signal propagation proceed as:
- Initial stage: where $r_0=[1,1,…,1]^T\in\mathbb{R}^{d_\text{node}}$
- Subsequent propagation:
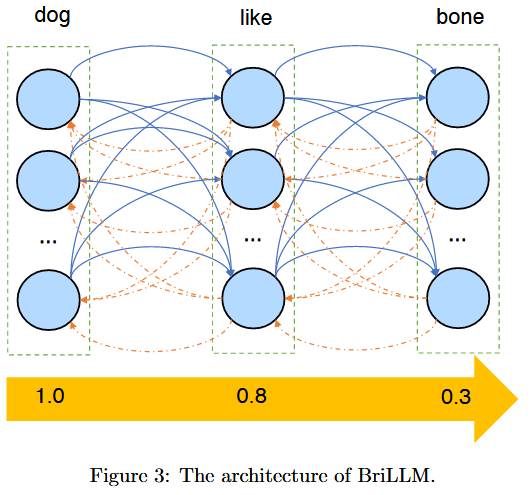
Next-Token Prediction
Prediction integrates signals from all prior nodes using attention weights $\alpha\in\mathbb{R}^{L-1}$:
- Attention normalization: $A=\text{softmax}(\alpha_{1:L-1})$
- Signal aggregation: $S_L=\sum^{L-1}_{k=1}\mathcal{A_k}\cdot \mathcal{r_k}$
- Prediction: $v_L=\arg\max_{v’\in V}\lVert S_L^{(v’)}\rVert$
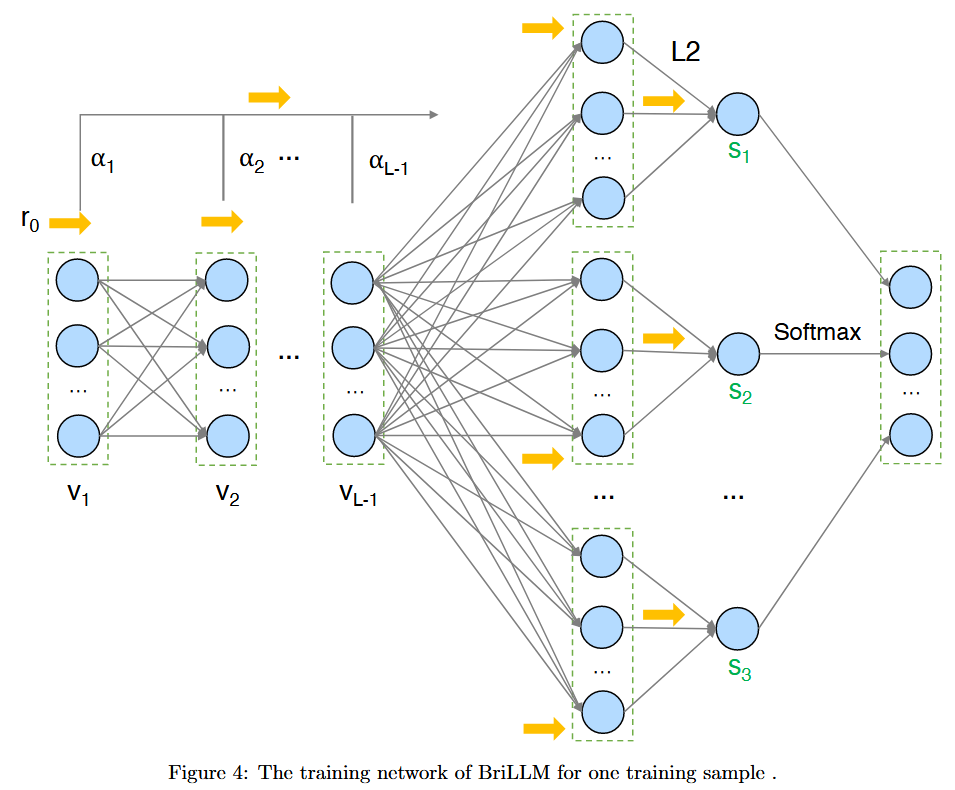
Training Process
Training constructs a dynamic MLP network for each sequences with $L+2$ layers.
- First $L-1$ layers: Connecting nodes $v_1,v_2,…,v_{L-1}$
- $L$-th layer: Concatenates all nodes
- $L+1$-th layer: L2 normalization layer
- $L+2$-th layer: Softmax layer
Cross-entropy loss rewards cases where the correct node exhibits highest energy. “Signal reset” strategy is used to control backpropagation depth by terminating gradient computation at fixed intervals, making the training feasible for long sequences.
Optimization directions:
- Improved network architecture to optimize the BriLLM training network construction
- Non-backpropagation brain-inspired training algorithms aligned with SiFu’s competitive activation nature
Experiment
Setup: 8 NVIDIA A800 GPUs
Dataset: Wikipedia (Chinese & English, each 100M tokens)
Configurations
- Sine-cosine positional encoding
- GeLU activation function
- Cross-entropy loss
- Nodes $d_\text{node}$ = 32 (neuron per node), with edges $32\times32$ matrices
- AdamW optimizer ($\beta_1=0.9,\beta_2=0.999$)
- Steps= 1.5K
- Total parameter $\approx$ 1.6B

Learning Scalability
Training loss decreased steadily and monotonically across iterations, with perplexity (PPL) reducing from 604.16 to 2.18 over 1,500 training steps. This confirms that BriLLM effectively learns language patterns only via signal energy optimization, rather than vector shape re-encoding.
Reference
[1] H. Zhao, H. Wu, D. Yang, A. Zou, and J. Hong, “BriLLM: Brain-inspired Large Language Model,” Sept. 08, 2025, arXiv: arXiv:2503.11299. doi: 10.48550/arXiv.2503.11299.