Revisiting Long Context Modeling From Context Denoising Perspective
Table of Contents
Source: “Revisiting Long-context Modeling from Context Denoising Perspective,” arXiv: arXiv:2510.05862
Introduction
Background
The advancement of long-context model (LCM) has emerged significantly to handle up to millions of tokens. However, some researchers found out the problem of LCM to be impacted by contextual noise such as irrelevant tokens that will mislead the attention of the model.
Objective
Develop an effective method to mitigate the context noise the the long-context inputs to improve the model’s ability on giving better attention on the critical tokens
Conclusion
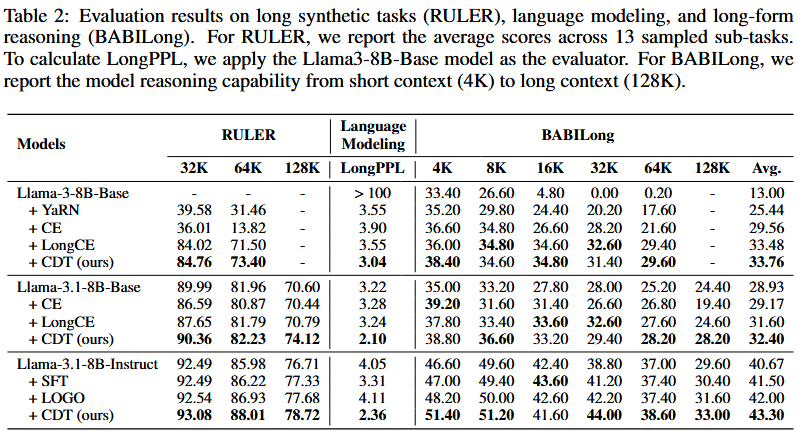
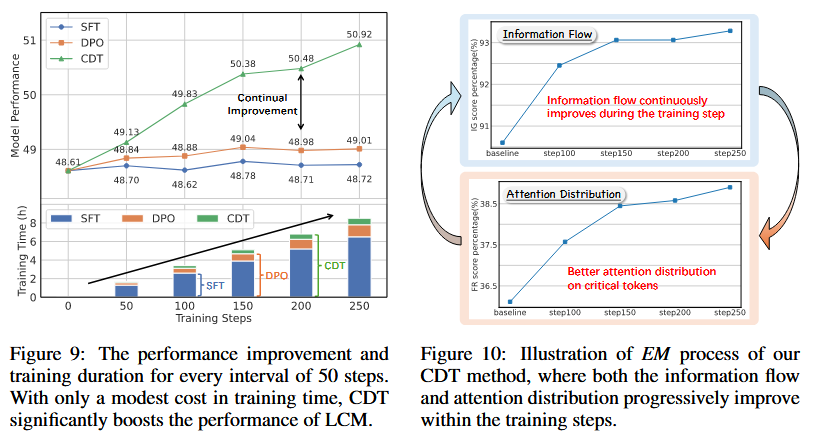
This paper introduces context denoising training (CDT), an approach detects noises using integrated gradients and suppress them during training to improve long-context capabilities. The results shows that 8B models can achieve comparable performance comparing to GPT-4o on real-world tasks and significant gains on synthetic benchmarks.
Literature Review
“LCMs first retrieve salient information within the context and utilize this information for further prediction” (Source: Chapter 2.1)
From the above observation stated by other researchers, its being stated the model often have issues on extracting the correct focus in the given input. The solutions given by researchers are:
- Model architecture improvements
- Enhancing information extraction mechanism
- Optimizing training objective
Focusing on context denoising aspect, specifically long-context post-training. This method can be classified into two types: context window scaling and long-context alignment.
Context window scaling will extend the context length with limited computational cost comparing to pretraining. It can be split into two approaches: positional extrapolation and model architecture modification.
Long-context alignment aims to enhance the ability of model with long-context capabilities and to address alignment challenges like hallucination.
Methodology
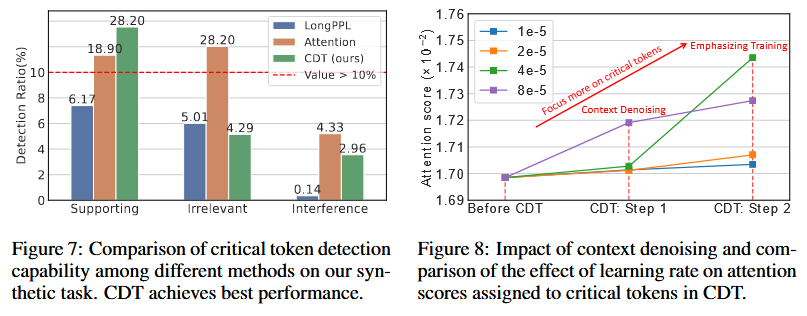
Critical Tokens Detection
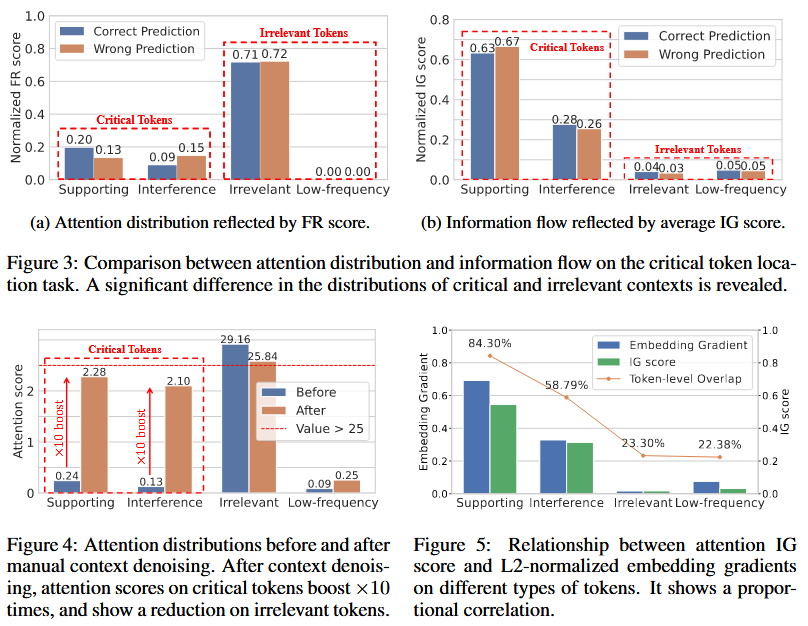
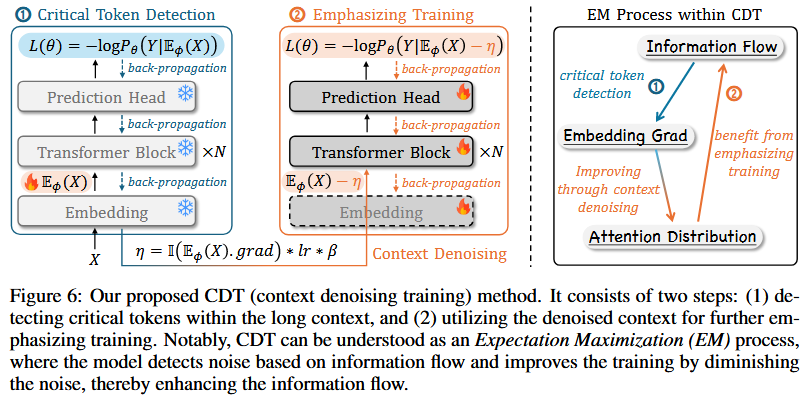
Experiment Design: Injecting irrelevant documents and low-frequency words into long-context window
Two new metrics in evaluation for the influence of context noise:
- Fact Retrieval (FR) Score
- Integrated Gradient (IG) Score
Symbols notation:
- $X = {x_i}^n_{i=1}$ : Model input with $n$ tokens
- $Y = {y_j}^m_{j=1}$: Ground truth with $m$ tokens
- $h$ : Index of attention head
- $l$ : Index of model layer
- $s_j$ : Set of tokens attended by an attention head $h$ at generation step $j$
- $\mathcal{T}_r$ : Context token set of type $r \in [\text{sup, inter, irr, low}]$
- $\mathcal{L}_\theta(Y\mid X)$ : Model’s prediction loss on $Y$
- $A_{h,l}$ : Attention matrix of the $h$-th head in the $l$-th layer
- $f_\theta$ : Model
- $E_\phi(X)$ : Input token embeddings
- $lr$ : Learning rate
- $\beta$ : Hyperparameter of denoising level
Here IG score is a matrix, where each entry $\text{IG}_{h,l}[i,j]$ represents the estimated bidirectional information flow between token $x_i$ and token $y_i$. To access the overall impact, the total contribution of tokens in $\mathcal{T}_r$ to the final prediction $Y$ and average across all attention heads and layers are calculated as the final score. Higher $IG$ indicates larger contribution of $\mathcal{T}_r$ to $Y$.
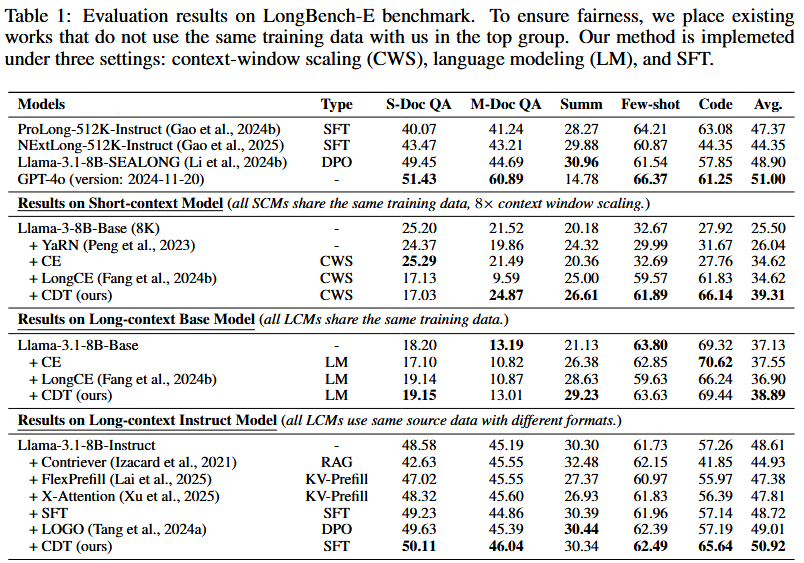
Context Denoising Training
Critical Token Detection
Identifier calculation:
where $\mathbb{I}(x_i)=1$ means $x_i$ is irrelevant token (noise), else critical token
Emphasizing Training
Denoised token embedding:
This is the new embedding use for further training, while the loss function is formulated as below:
Experiment
Setup: 8 * 92GB H20, using config of sequence length up to 12K
Tasks trained on:
- Real world tasks
- Language modeling task
- Long-form reasoning task
- Synthetic task
Models used:
- Short-context models (SCM): Llama-3-8B-Base (64K context length)
- Long-context models (LCM):
- Llama-3.1-8B-Base
- Llama-3.1-8B-Instruct
Dataset Used:
- Evaluation: LongBench-E, RULER
- Context window scaling of SCM to LCM : PG-19 (64K tokens * 10000 samples)
- Training: LCM-Instruct (Sampled from LongMiT & LongAlpaca with over 8000 samples context length from 16K to 128K)
Configuration:
- $\beta$ : 5
Reference
[1] Z. Tang, B. Ji, J. Li, L. Wu, H. Gui, and M. Zhang, “Revisiting Long-context Modeling from Context Denoising Perspective,” Oct. 07, 2025, arXiv: arXiv:2510.05862. doi: 10.48550/arXiv.2510.05862.